2020 年,帕特里克·刘易斯 (Patrick Lewis) 在一篇开创性的论文中首次提出了“检索增强生成 (Retrieval-Augmented Generation, RAG)”的概念,将其视为提升生成式 AI 模型准确性和可靠性的关键途径。这一术语很快获得了业界的认可,尽管近期刘易斯对其略显粗犷的缩写表达了歉意。
随着 AI 技术的演进,越来越多的 AI 代理集成了多样的生成模型,因此理解 RAG 等概念变得至关重要。对于 AI 爱好者而言,掌握 RAG 的原理不仅有助于推动个人项目的发展,也为在 Theoriq 协议上构建动态 AI 代理及其集群提供了理论依据。
RAG 是什么?
检索增强生成,简称 RAG,是一种增强 AI 提供准确、最新回应的能力的技术。设想一下,当你询问 AI 一个问题时,它能够迅速从互联网或大型数据库中检索出最新信息,这便是 RAG 的核心作用。借助 RAG,大型语言模型(Large Language Model, LLM)可以利用最新的事实数据来回答问题,而不仅仅是依赖其预训练时的数据。
预训练数据的意义
要深入了解 RAG,首先需要明确预训练数据和 LLM 的工作原理。LLM 是通过对大量的文本数据进行训练来学习语言规则和执行基本语言任务的,从而具备一定的理解和生成人类语言文本的能力。不过,传统的预训练模型存在以下几个限制:
静态信息:由于信息是在模型训练完成时固定下来的,因此随着时间推移,模型的知识库不会更新。
偏见和不准确性:模型可能会再现训练数据中的偏差或错误,这些偏差或错误并不总是反映现实情况。
缺乏实时信息:LLM 无法获取最新的事件或数据更新。
这也是为何现有的 AI 聊天机器人(如 ChatGPT)不能作为搜索引擎使用的原因。尽管它们能生成富有创意的回答,但在处理实时信息和真实场景时仍显不足。
RAG 如何提升 AI 代理的表现
假设你向一个 AI 代理询问:“今天我应该穿什么?” 如果没有 RAG 的支持,它可能会给出一个笼统的答案,例如“穿些舒适的衣服吧,比如牛仔裤和 T 恤”。然而,借助 RAG 的力量,相同的 AI 可以扮演“造型师”的角色,查询最新的天气预报,考虑你的穿着场合,并分析时尚潮流——进而给出更适合你需求的着装建议。
在 Theoriq 中,我们定义 AI 代理为一种自主软件系统,它利用现代生成式 AI 模型进行规划、访问数据、使用工具、作出决策,并与现实世界互动以执行特定功能。— Theoriq 团队,2024 年。
RAG 的工作流程
典型的 RAG 流程涉及将文档分解成更小的片段,计算每个片段的嵌入,并将它们存储在向量数据库中。当接收到问题时,系统会根据相似度度量来检索最相关的文档片段,这有助于 LLM 生成更加准确和贴切的回答。此过程中还可能包含重新排序或过滤检索信息等中间步骤。
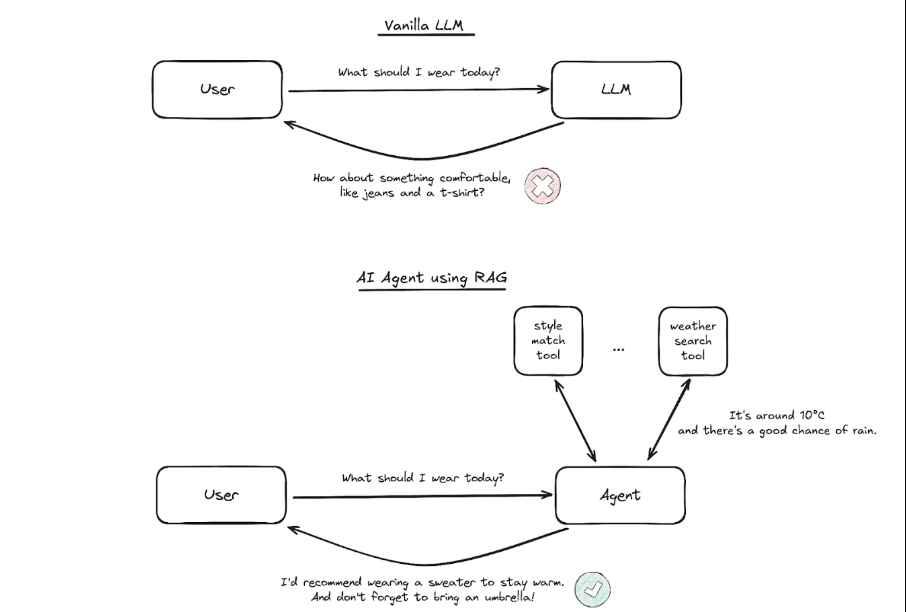
通过这种方式,RAG 不仅增强了 AI 的反应速度和准确性,还显著提高了用户体验。随着 RAG 技术的应用日益广泛,它将继续推动 AI 发展的新边界。
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐

加密货币市场高度依赖比特币,但比特币的设计缺乏直接支持去中心化金融(DeFi)的机制。目前市场上的大多数 DeFi 项目都使用其生态系统内的原生代币,这让用户资金面临风险。即使有 DeFi 项目使用比特币相关产品,通常也需要将比特币封装或放弃资产控制权,比如 WBTC 和 RENBTC。Side Protocol 通过提供安全的原生比特币 De...

zkLink 是一个由 zk-SNARKS 加固的紧密集成的多链交易框架。它促进了先进的去中心化交易解决方案的开发,包括订单簿 DEX、NFT 市场和其他应用。zkLink 的全面多功能 ZK-Rollup 中间件使开发者和交易者能够在不同链之间利用共享的资产和流动性。通过将多种 L1 区块链和 L2 网络相互连接,zkLink 提供了无缝的多链交易体验,提...
 基于区块链技术的数字市场")
AgriDex 是一个基于区块链技术的数字化市场,旨在提供低成本以及在整个农业价值链中具有透明性的即时结算的系统,以提升农业贸易效率。该平台解决了农业行业中的一些重大难题,比如高额汇款费用(通常为每笔交易的 3% 至 6%,在考虑外汇点差时甚至高达 10%),以及通常需要三到七天的缓慢结算时间。关于 AgriDexAgriDex 是一...

SOLO 协议旨在解决以太坊独立验证者面临的高参与门槛和流动性限制问题,透过支持无需许可的铸造流动性质押代币(LST),SOLO 协议将独立验证者的入门成本降低至仅需1.25 ETH,并允许他们有效地借款来抵押原本缺乏流动性的质押部分,文中详细介绍 SOLO 协议的机制,包括铸造与销毁流程、清算与罚没处理、资金费率设定以及反集...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图
 简介-产业-托破Tuopo")
 简介-产业-托破Tuopo")