核心要点:
Rollup 是一种将交易排序任务从 L1 迁移到 L2 的技术。通过在 L2 上执行交易并在 L1 上进行结算和验证,不仅继承了以太坊 100%的活性与去中心化特性,还显著优化了 L2 的性能。
Taiko 是一个 Type-1 zkEVM,提出了 Based Contestable Rollup(BCR)和 Based Booster Rollup(BBR)两种创新框架,可以很好地扩大 Based Rollup 的技术优势。BCR 引入多重证明系统和争议处理机制,提高了网络安全性;BBR 则通过分片执行交易和存储,提升了链的扩展能力。
Puffer UniFi 是一个基于 Eigenlayer 的重质押协议,实现了基于 L1 的排序、预确认、Rollup 跨链操作、便于开发创建专用链等。这些创新解决了传统 Based Rollup 的一些限制,以确保价值回流到以太坊的基础层。
虽然 Based Rollup 还在早期探索阶段,面临一些技术限制和共享排序器路线的竞争压力,但它在安全性、去中心化和简洁性方面的优势使其有潜力成为未来 Rollup 技术的重要发展方向,有望以釜底抽薪式的创新引领出一条更加符合去中心化精神的 Rollup 之路。
作为一项将交易排序功能从 L2 整合至 L1 的技术方案,Based Rollup 自 2023 年 3 月由以太坊基金会研究员 Justin Drake 提出以来,已迅速被 Taiko、Puffer Finance 等协议采纳并处于持续创新中。本文将深入剖析其运作机理、独特优势及当前面临的挑战,同时展望其在区块链领域的广泛应用前景,彰显其作为 Rollup 变革推手的深远意义。
Based Rollup 应用背景和原理
背景:L2、Rollup、排序器
过去几年业内探索以太坊扩容的重要经验是,在不触动安全性和去中心化的情况下拓展单片区块链是非常困难的,因此社区和开发者的共识是通过将交易执行由 Layer1 迁移到 Layer2(以下简称 L2)上来缓解高规模的吞吐量要求,而 Rollup 技术无疑是目前实现该方案的核心路线。
简单来讲,Rollup 机制由 L1 上的一组智能合约与 L2 的网络节点共同构成,其中 L2 负责打包并执行交易,而 L1 则负责结算、共识和数据发布性的验证,以此确保交易的安全与可靠。由此,Rollup 通过将大量交易处理移至 L2 链下,可以极大地减轻 L1 即以太坊主网的负担,并能显著降低交易费用,为区块链的广泛应用铺平了道路。
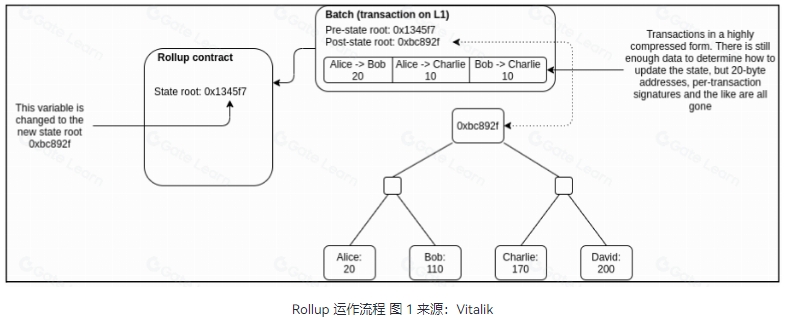
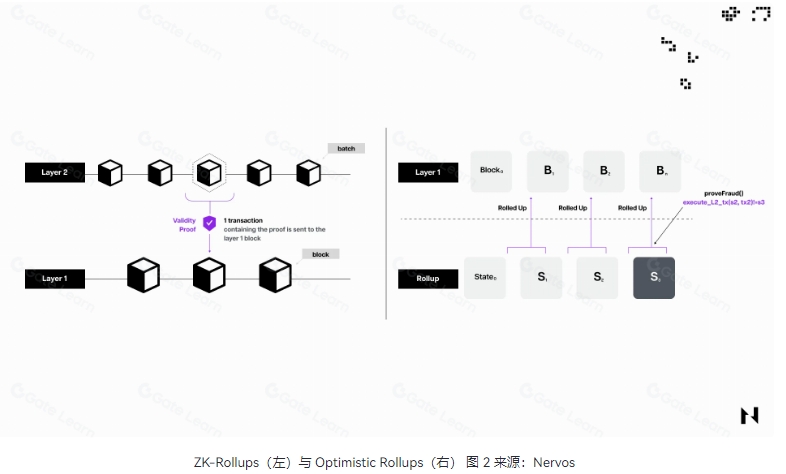
Rollup 分为两大主要类型 ZK Rollup 与 Optimistic Rollup。
ZK Rollup 通过发布零知识证明来验证链下交易的正确性,确保高度的安全性和隐私性,但部署比较复杂且需要耗费硬件设施。而 Optimistic Rollup 则采用了一种更为乐观的策略,仅在发生争议时才提供欺诈证明,这种机制虽在验证效率上有所提升、更具成本效益,但伴随的是争议解决或提款周期的延长。
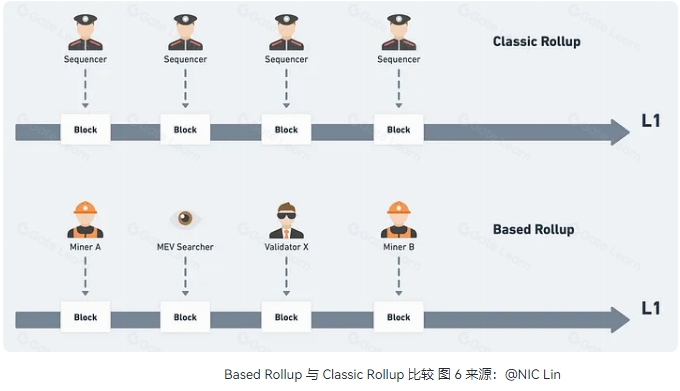
而在 Rollup 的架构中,排序器(Sequencer)作为 L2 网络节点的核心组件,承担着接收交易请求、确定执行顺序、打包成批次并传递给 L1 智能合约的重任,起到了提高交易处理效率和用户体验的重要作用。
以采用 Optimistic Rollup 的 Arbitrum 为例,交易由排序器以 FCFS (First Come First Service,先到先得)方式排序,一旦排序器确认交易有序,它就会将排好序的交易写入 L1 (即 Ethereum 主网)网络上的区块中,排序器就会立即提供「预确认」(或软确认),让用户知道交易在 L1 上完成之前已在 L2 上完成。
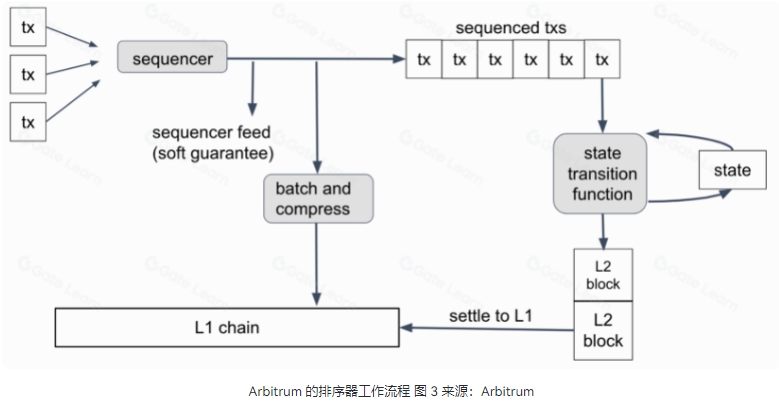
但是,如果排序器在此过程完成之前崩溃或报错,则用户的交易将保留在 L2 中,而不会在 L1 中完成。由此不难看出,这种使用单个排序器可能面临交易延迟、崩溃停机等隐患,而这种情形也确实真实发生过。
不难发现,这种中心化排序器会使以太坊主网在结算层维度对 L2 的掌控力显著减弱,容易出现恶意审查用户交易、出错、榨取 MEV、抢跑、流量碎片化甚至强制停机(如 Linea、Blase 因资产被盗就直接停机)等风险,进而影响整个 Rollup 系统的稳定性和安全性。
总之,这种集中化的设计赋予了排序器过大的权力,已成为目前业内担忧的焦点。
Based Rollup 的技术破局
Rollup 将排序器交给以太坊主网执行的观点最早可追溯至以太坊创始人 Vitalik Buterin 在 2021 年初的观点,他认为应实现一个高度灵活和可扩展的区块链解决方案,即「Total Anarchy(无政府)」Rollup,允许任何人无限制地扩展交易。
他还与后来 Based Rollup 的提出者 Justin 在当时指出了实现这一目标的方案,即提议者-构建者分离(Proposer-Builder Separation, PBS)的创新概念。在此框架下,区块提议者的角色发生根本性转变,不再自主构造收益最大化的区块,而是转向依托一个市场机制,该机制允许多方参与者向提议者推送 Bundles(对于 L2 而言,则为 Rollup 区块)。提议者随后从这些候选 Bundles 中选取费用最高者进行提交,这一过程类似于区块层面的 MemPool 机制,有效限制了区块提议者的自主权力,避免了全网范围内无节制地搜索最优交易,转而从预设的资源池中筛选现成区块。
此机制的设计灵感,类似于城市交通管理中对出租车运营区域的限制,确保服务提供者(提议者)在特定范围内(市场)竞争,减少了跨区域无序竞争导致的效率低下,如长途小单被忽视的问题,有助于将区块构建的决策权从 L2 转移到主网层面,实现更为集中和有序的区块生产流程。
而很显然,目前几乎所有 Rollup 解决方案都仍处于使用 「辅助轮」(training wheels) 的阶段,这意味着现阶段的 Rollup 还没实现去信任或者信任最小化。
结合现有 Rollup 方案在排序、验证和执行等方面存在效率瓶颈和信任问题,很多人提出了应对方案。
Rollkit sovereign Rollups 较早提出了「pure fork-choice rule」 ,它明确了这种技术需要在执行层解决资源定价或拒绝服务(DOS)向量的问题。例如,如果某个数据包包含了一个无限循环(如 while(true))并消耗了最大量的 gas,Rollkit 主权汇总会采取一种消耗(burn)或其他类似措施来应对。
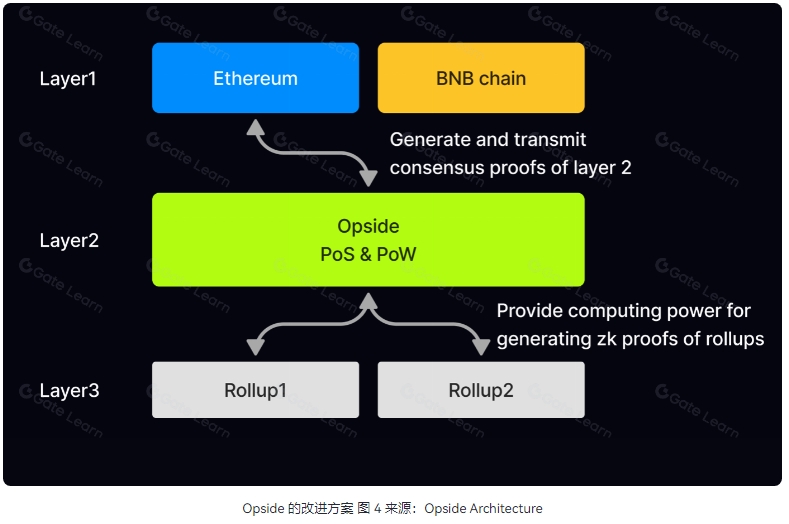
甚至 Opside 也较早提出了比较 Native 的方案,指出应采用改进的 ETH 2.0 PoS,允许 IDE 质押成为验证者,同时验证者在 Layer 3 担任排序者及证明者角色,排序者提出区块,证明者则生成 zk 证明验证区块,首个提交有效证明者获区块奖励。
而正式提出基于 L1 主网来进行排序的 Native 想法则要归功于以太坊基金会的研究员 Justin Drake,他在 2023 年 3 月(实际上,根据材料,他首次提出这一概念的时间可能更早,但此处我们按照「2023 年」这一时间点进行整合)的博文中首次完整提出了 Based Rollup 的雏形。
「当汇总的排序由基础层(L1)驱动时,我们称其为基于 L1 或由 L1 排序的 Rollup。具体地说,基于 L1 的 Rollup 是指下一个 L1 提议者可以与 L1 搜索者和构建者合作,无需许可地将下一个 Rollup 区块包含在下一个 L1 区块中。」
该思路旨在通过将排序权利外包给以太坊 L1 的验证者来克服现有 Rollup 的局限性,因其更加贴合、基于 L1 的密切关系,所以 Justin 将其称为 Based Rollups 或 L1-sequenced Rollups。
这种设计允许 L1 的提议者与 L2 的搜索者和构建者无需许可地协作,将 Rollup 区块直接包含在 L1 区块中。通过这种方式,Based Rollup 实现了排序权利的集中化和信任的最小化,因为所有的排序操作都由以太坊 L1 的验证者完成,这些验证者已经经过了严格的筛选和信任验证。
Justin Drake 在提出 Based Rollup 概念时,还提出了一个创新性的想法:重用以太坊的验证者来验证 Rollup 的交易。这一想法的出发点是,随着 Rollup 数量的增加(包括通用型和应用专用型 Rollup),需要一种通用的解决方案来验证这些交易。通过利用以太坊现有的验证者池,Based Rollup 能够显著降低验证成本和提高验证效率。
随着近期 Taiko、Puffer Finance 等采用 Based Rollup 方案,Vitalik、Justin 等都进一步阐释了该技术路线的更多远景,从而引发了一定的市场关注。
当然 Based Rollup 相较于其它扩容方案,仍处于较早期的探索阶段,我们将在下文探讨其技术细节和应用场景。
Based Rollup 技术解析
Based Rollup 的技术要点是把排序后的交易状态变化发布到 L1 即可从 L2 中提取 MEV,让所有的排序和安全性由以太坊 L1 提供。
技术原理
Based Rollups 摒弃了独立的排序器设计,将排序任务交由 L1(如 Ethereum 主网)的节点执行,包括 L1 的搜索者或其他任何人,都可以将 Based Rollups 的交易信息无需许可地提交给 L1 的区块出块者。这些搜索者和构建者(可能由 Based Rollup 或第三方激励)负责将 Rollup 的交易信息整合进区块并提交。
通过将排序工作下放给 L1 的出块者,Based Rollup 的设计将变得简洁,能够使 L2 专注于执行效率,同时继承了 L1 的去中心化特性,并在经济模型上与 L1 紧密整合,因为交易费用直接支付给 L1 的节点(如以太坊节点)。
换言之,Based Rollup 的共识层、数据发布层、结算层均基于以太坊,仅执行层构建在 Rollup 网络之上,专门处理交易执行和状态更新。
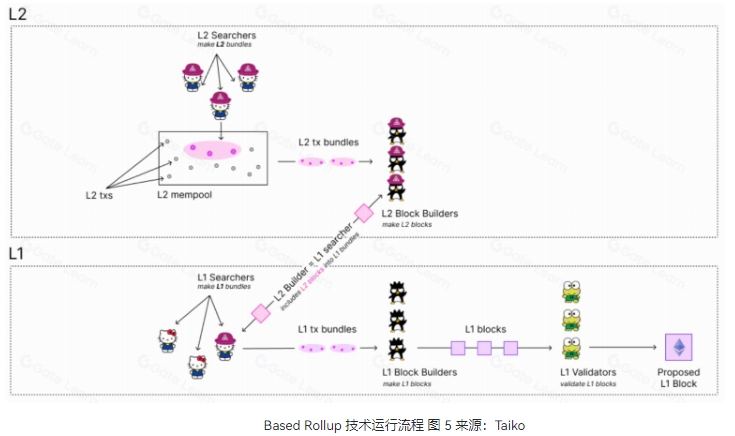
运行流程
Based Rollup 的运行机制是,L2 搜索者收集交易成 bundles(捆绑包)发送给 L2 区块提议者,后者构建成 L2 区块,最终由 L1 搜索者将这些 L2 区块包含进 L1 区块中完成排序和记录。
L2 搜索者收集交易:L2 搜索者将 L2 交易收集成 bundles,并发送给 L2 区块提议者。
L2 区块构建:L2 区块提议者接收来自 L2 搜索者的 bundles,并据此构建一个 L2 区块。
L1 包含 L2 区块:最后,L1 的搜索者将这些 L2 区块(或其 bundles)包含在 L1 的区块中,从而完成排序和记录过程。
Based Rollup 的优势与挑战
Based Rollup 优势
Based Rollup 的核心优势在于通过将交易排序责任转移至 L1,这不仅继承了以太坊 100%的活性与去中心化特性,还显著优化了 L2 的性能。该方案无需额外安全机制,简化了技术复杂性,减少了延迟,并降低了操作成本。
在经济激励上,L1 矿工因参与 L2 交易排序获得额外收益,增强了网络整体健康与经济安全性。
具体而言,这些优势包括:
活性(Liveness):活性是指 Based Rollup 可以避免传统 Rollup 或贡献排序器因排序故障或特定审查,导致网络中断或故意不支持特定使用者的交易,全程无需逃生舱机制,确保交易快速有效。
去中心化:启用 L1 的搜寻者、构建者与出块者基础设施,保持高度去中心化以及开放、透明的 Web3 精神。
简洁性:Based Rollup 继承了以太坊 L1 的安全性和去中心化,因为它们重用了底层验证器堆栈和 PBS 基础架构,无需 L2 自有或中间件共享的排序器签名验证、逃生舱或外部 PoS 共识,降低了技术复杂性与安全风险。
成本效益:L1 处理排序后,L2 交易批处理与确认更高效,不必像 Optimistic Rollup 和 ZK Rollup 那样需要维护一套复杂的基础设施和能源消耗来处理和验证 L2 交易,尤其在交易量大时成本效益更明显。
经济激励一致性:MEV 流向 L1 增强了经济安全,有助于增强以太坊的经济安全性,从而增强其作为结算层的价值,同时 L2 可从拥堵费中获取收入,保持一定程度的经济自主性。
主权性:尽管排序依赖 L1,但 Based Rollup 仍保留治理代币、收取基本费用及自主使用这些收益的权利,确保其在生态系统中的独立地位,而 L1 也可以确保价值回流巩固其基础层的主权地位,减少 L2 各自为政造成的生态系统碎片化、无序低效的后果。
Based Rollup 挑战
内在的机制和技术限制
Based Rollup 在提供显著优势的同时,也存在一些不容忽视的机制和技术限制,这反过来阻碍了 Based Rollup 技术的推广实施:
收入限制与 MEV 收益流失:由于排序任务依赖于 L1,大部分 MEV 收益流向 L1 验证者,由此限制了 Based Rollup 自身的收入来源。这可能导致项目方的可持续性和盈利能力受到质疑,这也是目前大部分 L2、RaaS 项目方在该方向进展不太积极的基于利益考量的背景。
排序灵活性与策略受限:将排序职责交给 L1 会降低交易排序的灵活性,影响如 FCFS 等特定排序策略的实现,而如果引入额外的技术支持来弥补该不足,又会增加协议设计的复杂性和实现难度。此外,L1 排序可能更多地基于矿工利益最大化,而非 Based Rollup 用户的最佳利益。
交易确认速度会延迟:理论上讲,Based Rollup 交易确认时间直接取决于 L1 区块时间(目前以太坊的区块时间是 12 秒),这显然会影响用户对即时性的要求。尽管存在通过重新抵押机制实现预确认的解决方案,但该方案还不成熟且不具普遍性,笔者在后文提及 Puffer Finance 用例时会对此做初步探讨。而一个有趣的现实悖论是,最初的 Arbitrum implementation 和第一个公共测试网(Ropsten L2)恰好就是这种 Native Rollup 的排序设计,但后来正是因为对于快速交易的需求而替换成了 L2 自有的中心化排序器,所以这种切换会原本的排序方式又会导致无法满足快速交易,会被视为某种程度上的「开历史倒车」。
去中心化程度的潜在影响:虽然 Based Rollup 继承了 L1 的去中心化特性,但为捕捉 MEV 收益而设计的出块权利竞标机制可能提高 L1 参与门槛,并引入额外的复杂性。
合理安排各角色职能的障碍:很多研究都忽略了 Based Rollup 在推翻原有排序器方案之后,如何合理调度各环节角色的现实障碍。笔者认为,虽然 MEV 流向 L1 为验证者提供了经济激励,但如何将验证 Rollup 的逻辑内置到以太坊协议本身、如何制定分配搜索者与验证者的 MEV 利润分配和激励措施、如何规避多个搜索者同时批量提交交易造成的拥堵或共识处理等悬而未决。当然,Taiko 等项目也对此做了一些技术破局,笔者会在后文做详细解释。
外部的路线竞争压力
此外,Based Rollup 还面临着与其它优化排序器方案的路线竞争压力。目前除了 Based Rollup 这种直接丢弃 L2 自身或有赖于外包排序器的技术方案,还有很多创新易用的方案。
首先是在证明机制或各类验证方法上进行整合的微小改动,例如 Polygon 的 PoE 共识算法直接在 Rollup 网络层面实现去中心化排序。
其次是单独推出去中心化的排序器架构,例如 Metis 通过构建由多个节点组成的排序器池,并采用随机轮换机制及节点质押、PoS 共识层管理多签密钥、验证者抽样检查等策略,实现了去中心化排序器的运行;Espresso 则通过构建模块化排序器中间件,作为中间层为 L2 统一提供共享的排序「外包」服务;Flashbots SUAVE 推出一条 EVM 兼容链,专门用于通过区块「竞标」的方式实现交易排序。
再比如 Eigenlayer 与 AltLayer 合作开发的 SQUAD,它被设计为一个开放给任何 EigenLayer AVS(Actively Validated Services)运营商加入的节点网络,引入最低要求的 LST 质押,或实施委托质押机制,从 Rollup 中注册排序需求并将其与排序器进行匹配。
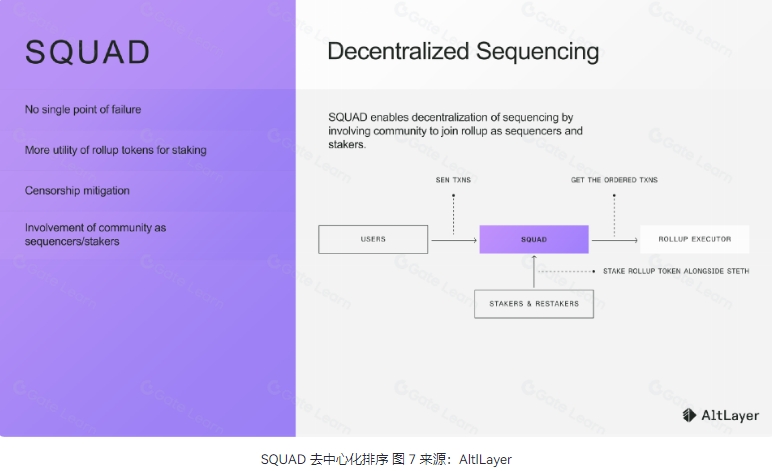
这里多说一句,笔者目前看到市场有一种 AVS 与 Based Rollup 竞争的论调,其实它们之间的关系并不大。因为 Based Rollup 主要涉及区块提议的方式,而 AVS 则是为那些不能直接在以太坊上部署的 DAPP 提供 POS 或其它共识的底层网络安全验证,这两者并没有技术上的直接冲突,反而我们看到最近 Eigenlayer 再质押结合 Espresso 去中心排序器,可以赋予 L1 验证者参与排序器运行的权力,这在一定意义上是会促进 Based Rollup 的采用率,当然是否选择使用 L1 验证者参与排序的选择器的权利不在于 Eigenlayer 而是 Espresso 这样的项目方。
总之,把交易排序的执行角色由 L2 转给 L1,并不能解决所有问题反而又会派生出新的难题。我们也同时看到,很多人提到的 Eigenlayer 再质押协议、零知识证明(ZKPs)等确实可以在部分程度上弯道解决 Based Rollup 的先天缺陷,但目前却一直没有完善明确的解决方案,反倒是 Eigenlayer 等正在研发的共享排序器因保留了参与机制灵活性和实施难度,正在被普遍推广,这确实是目前 Based Rollup 所面临的较大的外部竞争的压力现状,当然这也意味着 Based Rollup 需要作出一定的技术融合来适配其应用场景。
Based Rollup 用例
由于 Based Rollup 的概念提出到现在仅有一年多的时间,属于老概念翻新,其理论和实现细节还在探索和完善阶段,所以正在构建 Based Rollup 的项目很少,我们下面简要分享三个实际用例。
Taiko:首个深度研究并应用 Based Rollup 的 L2
Taiko 是一个使用 ZK Rollup 技术的 L2,并开发了 Type-1 zkEVM,提供了与以太坊完全相同的操作码和功能,确保了与现有以太坊生态的高度兼容性。
在 Based Rollup 概念提出后不久,Taiko 便将自己定义为 Based Rollup,强调优先考虑以太坊等效性而非 ZK 证明生成的速度/成本,加之其做了诸多技术创新,所以自称是高度可配置、完全开源、无需许可、与以太坊相当的 Rollup。
技术架构
Taiko 早在 2022 年的博文中就介绍了其三个主要的部分:ZK-EVM(用于生成证明)、Taiko L2 Rollup Node(用于管理 Rollup 链)和 Taiko Protocol(用于将这两部分连接在一起进行 Rollup 协议验证)。
1.ZK-EVM:以太坊镜像
功能:ZK-EVM 是 Taiko 的核心计算引擎,用于生成证明以确保 Rollup 上 EVM(以太坊虚拟机)计算的正确性。它实现了支持每个 EVM 操作码的 ZK-EVM,并通过有效性证明来验证 Rollup 链上的所有计算。
特点:ZK-EVM 不仅保持了与以太坊 EVM 的完美等效性,还允许开发者无缝迁移和部署现有的以太坊智能合约和 dApp,无需进行任何代码更改。这意味着所有以太坊和 Solidity 工具都可以与 Taiko 无缝协作,从而保持开发工作流程的连续性和效率。
2.Taiko L2 Rollup Node:高效执行,安全验证
功能:Taiko L2 Rollup Node 是管理 Rollup 链的节点,负责从以太坊获取交易数据并在 L2 上执行这些交易。它基于以太坊 Geth 的分叉版本,使用与以太坊相同的哈希算法、签名方案和存储数据结构,以确保与以太坊的兼容性和互操作性。
特点:这些节点不仅管理 Rollup 链的状态,还确保交易的确定性和最终性。通过并行证明和去中心化的验证机制,Taiko L2 Rollup Node 能够提供高效且安全的交易处理服务。
3.Taiko Protocol:无缝桥接
功能:Taiko Protocol 是将 ZK-EVM 和 Taiko L2 Rollup Node 连接在一起的桥梁,用于定义并执行 Rollup 规则和潜在参与者的资格,确保网络的安全、去中心化和无需许可性。
特点:它是一组部署在以太坊上的智能合约,充当 ZK-SNARK 证明的数据可用性机制和验证者,而部署在 Taiko L2 上的智能合约则执行某些重要的协议功能。Taiko Protocol 通过严格的协议设计,确保所有提议的区块都是确定性的,并可以并行证明,从而提高了交易处理的速度和效率。
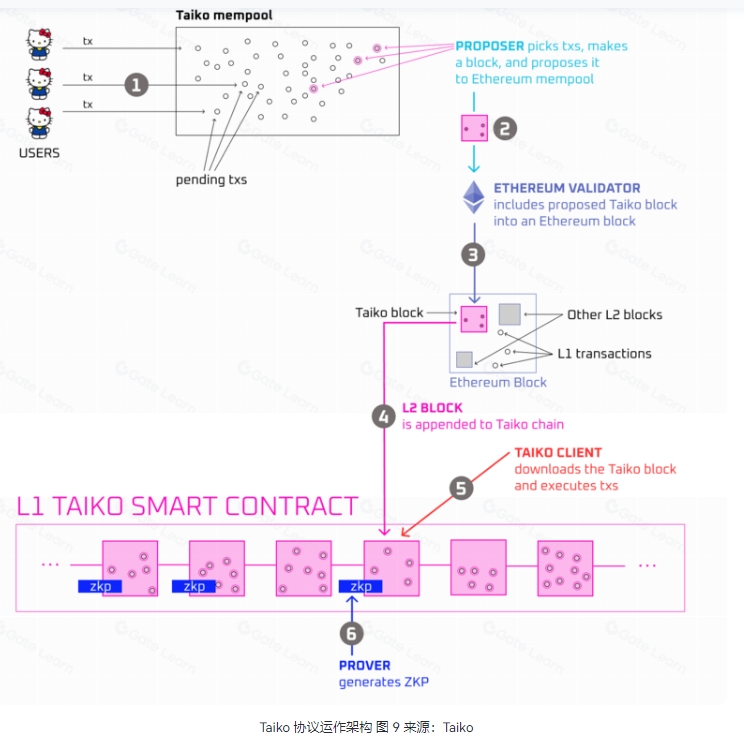
总的来说,Taiko 通过这三个主要部分的协同工作,实现了与以太坊的等效性、兼容性和扩展性。它不仅能够无缝迁移和部署现有的以太坊智能合约和 dApp,还提供了高效、安全的交易处理服务。
创新要点
Taiko 协议目前非常重要的创新是 BCR 框架(Based Contestable Rollup)和 BBR 框架(Based Booster Rollup,BBR),这两种创新方式可以很好地扩大 Based Rollup 的技术优势,我们这里做重点探讨。
BCR(Based Contestable Rollup):基于可竞争的汇总
BCR 基于 Multi-proofs (多证明者交互式证明)打造,将争议处理过程(类似欺诈证明系统)纳入了交易验证工作流程,多重竞争确保去中心化生成与验证,增强网络安全性。
工作流程
在这一体系中,任何个体均有机会成为提议者,提出区块构建方案,并附带零知识证明以确保交易处理的正确性与隐私保护。同时,若验证者对某一区块的状态转换结果存在质疑,他们可发起安全级别的挑战证明,尝试修正第二层(L2)的区块状态,从而在可能的正确与错误路径间做出裁决。
很多研究忽略的一点是 BCR 如何应对该过程中出现的恶意或轻率的竞争。事实上,该机制引入了自己的证明(own proving)和冷却窗口(cooldown windows),以及设定较高层级证明的有效性和争执保证金明显高于较低层级的证明。这样通过急剧攀升的成本,能有效阻止轻率或恶意的争执。
简单来讲,任何人可成提议者,提交区块与零知识证明,而验证者可对结果质疑,提交挑战证明,由此通过持续的验证挑战可显著增强网络的安全防护级别,确保每个区块的公正性和可信度。
特点
Taiko 在设计上重视灵活性和对安全性,同时也考虑了经济成本的平衡。
多重证明系统(Multi-proof system)
Taiko 的多重证明系统允许每个层级使用其证明系统。通过组合多个子证明者来构建更可靠的复合证明者,虽然成本递增,但安全性显著提升,既可垂直分层又横向整合多子验证者。
证明者可用性(Prover availability)
Taiko 实施动态层级分配,随机分配每个新块的最低要求层级,区块被分配更高层级的可能性与层级成反比。当面对资本密集型攻击,社区节点可通过争议保证金集体抵御无效证明,维护系统稳定。
动态配置调整(Dynamic configuration adjustments)
Taiko 设计具备高度适应性,允许系统根据高层级证明成本的变化,动态调整块的证明要求比例。这种灵活性使得系统可以从 OP 证明逐步无缝过渡到 ZK 证明,优化安全性和经济激励。
成本与安全权衡(Cost vs. security tradeoffs)
ZK-Rollup 虽安全,成本却对高交易量链构成挑战。Taiko 争议 Rollup 作为桥梁,让应用链从经济配置起步,逐步增强安全,无缝对接现有架构。
守护者证明者(Guardian provers)
守护者证明者在系统初期作为高层级证明者的安全网,处理证明系统中的错误。随系统成熟,其作用逐渐淡出,为初期阶段筑起关键安全防线,不干预交易排序。
BBR(Based Booster Rollup):基于助推器的汇总
BBR 是在 BCR 推出后的又一里程碑,这是一种开箱即用的原生 L1 扩展方法,将交易的执行和存储分片,可以理解为类似于为开发者的笔记本电脑添加额外的 CPU/SSD,便于开发者部署一次 dapp 后,自动快速地扩展到所需的全部 L2 上。
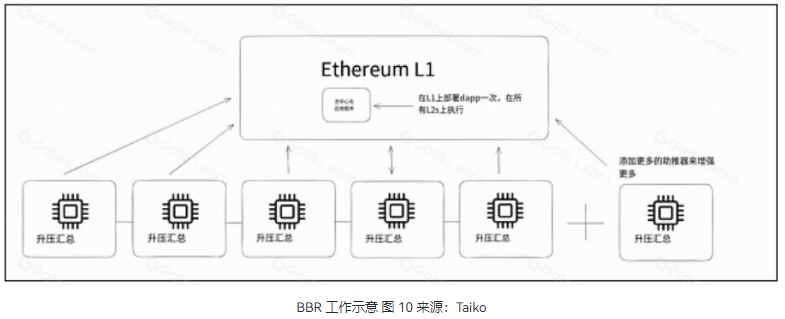
工作流程
下面是关键的实施细节
L1CALL 和 L1DELEGATECALL 预编译:
通过 L1CALL 预编译,L2 可以直接读取和写入 L1 状态。
L1DELEGATECALL 允许在 L2 上执行 L1 智能合约,但所有存储读写操作使用 L2 状态。
ZK-EVM 协处理器:
使用 ZK-EVM(零知识以太坊虚拟机)作为协处理器,将 L1 智能合约的工作卸载到 L2,同时保持所有状态在 L1。
仅需在 L1 上验证 ZK 证明并应用最终状态更新。
特点
去中心化和以太坊对齐
基于 Rollup 继承了 L1 的去中心化和简单性,避免了引入集中或半集中的排序风险。
自动扩展:dapp 只需在 L1 上部署一次,即可自动扩展到所有 L2,无需额外的设置工作。
高效的交易执行和存储分片
Booster Rollup 通过分片执行交易和存储的双层结构,提升了链的扩展能力。
ZK-EVM 协处理器
Booster Rollup 可以作为 ZK-EVM 协处理器,将所有 L1 智能合约工作卸载到 L2,同时保持所有状态在 L1。
减少碎片化
通过在所有 L2 之间添加原子跨 Rollup 交易,BBR 解决了当前 Rollup 面临的碎片化问题。
限制
当然官方对 BBR 框架也不讳言其缺陷限制,我们这里整合如下。
合约部署的局限:BBR 框架下,合约部署仅限于 L1,L2 无法独立部署新合约,仅能继承 L1 智能合约,限制了 L2 的独立扩展能力。
共享数据扩展瓶颈:BBR 高度依赖 L1 的共享数据,限制了数据可用性的扩展,所有处理仍需回溯至 L1,影响整体扩展性。
并行化挑战:并非所有 dApp 都能轻松适配 BBR 的并行模型,导致部分智能合约在 L2 的扩展受限。
严格的节点同步需求:BBR 要求 L1 与 L2 节点紧密同步,低延迟通信成为必需,提高了硬件门槛与运维复杂度。
初始化复杂性:L2 合约初始化需特别处理以确保数据一致性,增加了开发成本与潜在安全风险。
费用与数据可用性的复杂性:L2 处理费用虽便捷,但链上数据需求增加;同时,L2 交易需额外管理账户 nonce,提升了系统复杂度。
存储与计算的权衡困境:BBR 模式下,计算可优化至 L2,但状态更新仍需 L1 参与,存储密集型操作成本高昂。
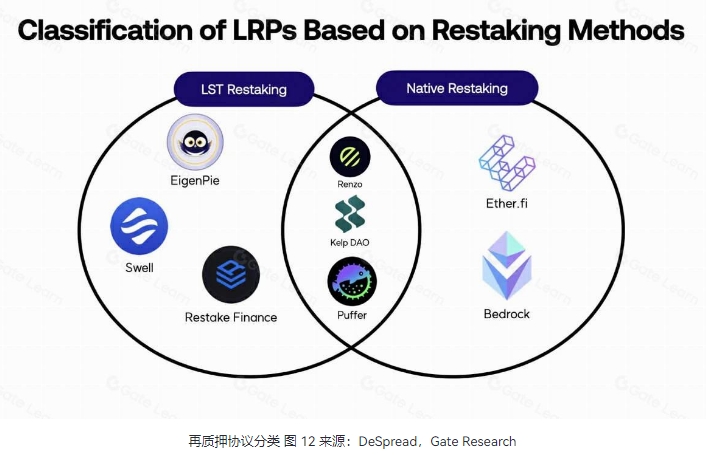
2 Puffer UniFi:Restaking 驱动下的创新型 Based Rollup
Puffer Finance 是一个基于以太坊重质押协议 Eigenlayer 构建的流动性质押衍生品 ( LSD ) 协议,目前 TVL 已超过 17 亿美元,居该赛道第三位。
Puffer Finance 在今年 6 月底宣布与以太坊基金会合作共同开发 Based Rollup,并在 7 月初推出对应的产品 Puffer UniFi 测试版。
技术架构
根据白皮书,当用户提交 Rollup 交易给 Puffer 验证器后,验证器就会通过预置确保交易将上链,并附加条件以维护可靠性,最终向以太坊 L1 提交包含已确认 Rollup 交易的区块。Puffer Sequencer 推进 Rollup 状态,同时 pufETH Vault 收集交易费用回馈给 UniFi 用户。
用户提交他们的 Rollup 交易,然后由 Puffer 处理验证器。这些验证器提供预置,确保用户知道他们的交易将包含在以太坊 L1 状态中。
Puffer 验证器重新质押并附加削减条件,以确保可靠性、接收来自用户的 Rollup 交易并发布预置。这些验证器已准备好将交易纳入 L1 区块中。
Preconf Slasher AVS 对验证者强制执行额外的削减条件,以阻止违背预先确认的承诺。
Puffer 验证者向以太坊 L1 提交区块。这些区块包括已预先确认的有序 Rollup 批次。
Puffer Sequencer Contract 接受分批交易。
pufETH Vault 收集汇总交易产⽣的拥堵费和竞争费。这些费用为 pufETH 持有者带来收益,并通过原生收益回馈给 UniFi 用户。
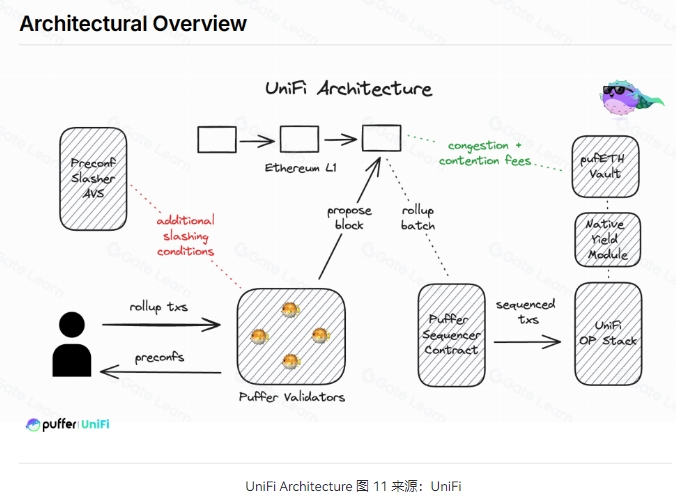
创新要点
根据其最新介绍,UniFi 借鉴了 Justin Drake 的研究见解,具体创新要点如下:
原生排序(Based Sequencing)
UniFi 直接利用以太坊在 L1 上的去中心化验证器,允许以可信中立的方式对交易进行排序,而无需依赖于中心化排序器。这意味着 L1 上的验证器负责 UniFi Rollup 内交易的排序。
预确认 (Preconfs)
UniFi 集成了一个预确认系统,该系统在用户的交易最终确定到 L1 之前,为用户提供快速、可靠的交易确认(约 100 毫秒)。这些预确认由 Puffer 的重新质押验证者发布,这些验证者受到激励以正确行事,否则将面临惩罚,例如削减。
笔者在这里补充一点,由于 Puffer 是少数支持 Native Restaking 的质押平台,所以可以指定其中一部分 L1 验证者承诺将基于 Rollup 的区块包含在他们将来提议的 L1 区块中,因为验证者至少提前知道 32 个区块,所以谁被指定为哪个区块的提议者,由此保证 L2 Rollup 块在主网中被包含,进而受主网保护,这样就可以解决确认上文提到的 L2 交易受 L1 出块时间慢的延迟问题。
去中心化排序器
该架构旨在从单个中心化排序器扩展到数以万计的去中心化排序器。这是通过利用 Puffer 的验证器集实现的,这意味着随着验证器数量的增加,网络变得更加去中心化。
同步可组合性
UniFi 中的交易可以直接与其他基于 Rollup 的交互,实现无缝交互而无需桥梁,消除了使⽤桥接器带来的延迟、额外成本、技术难度和安全风险,克服以太坊生态系统中碎片化和低效等关键挑战。
从上面不难看出,UniFi 凭借 Restaking 的质押机制,实现了基于 L1 的排序、预确认、Rollup 跨链操作、便于开发创建专用链等,并能有效弥补原有 Based Rollup 的诸多不足和限制,确保价值回流到以太坊的基础层。
RISE Chain:主打高性能的 L2
RISE Chain 建立在基于 Rust 的 Reth 节点基础设施之上,引入了新颖的状态访问架构、并行 EVM、连续块执行和分层 MPT。通过对 RISE DB 和互操作性的持续研究,RISE 致力于构建更具包容性和可扩展性的区块链生态系统。
根据 Justin 的整理,该协议同样采用 Based Rollup 技术路线,但目前尚处于白皮书阶段,暂无更多信息,这里仅做简单补充。
此外,笔者在梳理相关信息时还发现还有多个项目正在探索 Based Rollup 的应用,但均属于初步探索阶段,此处不再赘述。
结论
Based Rollup 作为一种返璞归真的以太坊 Rollup 扩展解决方案,通过将排序器的角色移交给 L1 自身管理,更加有效且政治正确,代表了以太坊 L2 扩展方式的巨大转变。
这种设计并非微小的技术改动,而是让 Rollup 专注于执行,安全要件回归 L1。其共识层、数据发布层、结算层都是以太坊,只有执行层构建在 Rollup 网络之上,负责处理交易的执行和状态更新。
在现实应用中,Based Rollup 践行者们正在凭借该方案的增强的安全性、去中心化特性及简化的系统开拓创新,至于其是否会成为 Rollup 的终极方案暂不可知,但在诸多中心化或半中心化排序器占 Rollup 主要份额的当下,Based Rollup 对多样化 Rollup 网络的创新的重要性不言而喻。
虽然 Based Rollup 发展面临市场和技术的双重验证,以及原有利益格局的抵触和诸多共享排序器方案的竞争,但随着 Taiko、Puffer Finance 等的不断开拓和创新,Based Rollup 将越来越具备显著的市场优势。
展望未来,Based Rollup 作为 Rollup 领域的革新路线,其创新的原生排序机制不仅攻克了透明性与单点故障的传统难题,更在 Rollup L2 解决方案市场中展现出强劲潜力,有望占据重要地位。我们期待通过更多开发者在收入模型、排序灵活性、用户体验、协议设计以及生态合作等方面的深入探索与优化,Based Rollup 将克服现有挑战,实现更广泛的应用场景与深远的发展,为以太坊生态系统带来更多的创新和发展机遇。
部分参考资料:
https://vitalik.ca/general/2021/01/05/Rollup.html
https://www.nervos.org/knowledge-base/zk_Rollup_vs_optimistic_Rollup
https://docs.arbitrum.io/how-arbitrum-works/sequencer
https://x.com/drakefjustin/status/1798734295332274408
https://abmedia.io/taiko-and-puffers-based-Rollups-will-change-the-landscape-of-ethereum
https://taiko.mirror.xyz/7dfMydX1FqEx9_sOvhRt3V8hJksKSIWjzhCVu7FyMZU
https://taiko.mirror.xyz/VjNjFws6OOVez5YCDMwjy4BUiDqZBHYDvcW4-JZGDkc
https://x.com/jason_chen998/status/1799692331635048697
https://ethresear.ch/t/based-Rollups-superpowers-from-l1-sequencing/15016
https://medium.com/@MTCapital_US/mt-capital-research-decentralized-sequencer-sector-comparative-research-4ca4621e1d8d
https://medium.com/ybbcapital/from-theory-to-practice-can-based-Rollup-achieve-l1-sequencing-driven-Rollup-solution-3dbfc3a45bef
https://vitalik.eth.limo/general/2022/08/04/zkevm.html
https://substack.chainfeeds.xyz/p/based-Rollup
https://medium.com/puffer-fi/get-ready-for-puffer-unifi-charting-new-waters-for-ethereums-ecosystem-e95482708ebb
https://medium.com/search?q=based+Rollup
https://taiko.mirror.xyz/oRy3ZZ_4-6IEQcuLCMMlxvdH6E-T3_H7UwYVzGDsgf4
https://blog.altlayer.io/introducing-restaked-Rollups-ac6a1e89b646
https://www.panewslab.com/zh/articledetails/pylr0ff1.html
https://vitalik.eth.limo/general/2024/06/30/epochslot.html
https://docs.altlayer.io/altlayer-documentation/restaked-Rollups/squad-for-decentralised-sequencing
https://defillama.com/protocol/puffer-finance
https://unifi.puffer.fi/
https://github.com/risechain/whitepaper/blob/main/RISE%20White%20Paper%20-%20Draft%20v0.5.pdf
https://www.panewslab.com/zh/articledetails/84vh6558.html
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐

数字时代彻底改变了品牌与消费者的互动,强调了吸引和保持注意力的重要性。传统广告方式往往干扰性强且单向,难以实现真正的互动。这一需求促使了更有效、回报更丰厚的系统的出现,以优先考虑真实的交流。Moongate正是为了解决这个问题而诞生的,它利用区块链技术来改善品牌与消费者之间的关系。这个创新平台使品牌能够通过...

MiL.k 是一个基于区块链的奖励平台,它让用户能够无缝整合和交易各种服务的积分奖励。在快速发展的生活方式市场(包括旅行、休闲、时尚和文化)中,企业日益依赖奖励积分来吸引和维系客户。但传统奖励系统的收益往往微乎其微,用户积累的积分不仅分散,还未能得到充分利用。随着市场竞争加剧,服务提供商单靠独立营销活动难...

Memecoins 是促进社区建设和培养归属感的强大工具,而这些都是加密货币市场中的关键因素。Mister Miggles(MIGGLES)正是这种现象的典范,其灵感来源于 Coinbase 官方 X 账号发布的一段关于喜马拉雅猫的病毒视频。Mister Miggles 很快赢得了广泛的喜爱,其相关内容迅速传播,因此 MIGGLES 被称为“Coinbase 猫吉祥物”。本报...

Yellow Card 是一个覆盖非洲多个地区的加密货币交易平台,提供通过当地货币买卖支持的加密货币(如BTC、ETH、USDT、ADA、SOL、USDC、Matic、XAUt和cUSD)的上/下车服务。该平台支持用户在非洲购买和出售比特币及其他加密货币,提供多种支付方式,并以低费用和具竞争力的汇率为特色。什么是 Yellow Card?Yellow Card 是一家专...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图

