你有没有想过,为什么像 Reddit、X(前 Twitter)这样的社交媒体可以免费使用?答案其实就藏在你每天发的帖子、点的赞,甚至只是停留的时间里。
曾经,这些平台将你的注意力作为商品卖给广告商。如今,它们找到了一个更大的买家——AI 公司。据报道,仅仅是 Reddit 与 Google 的一项数据授权协议,就能为前者带来每年 6000 万美元的收入。而这笔巨额财富,却与作为数据创造者的你我无关。
更令人不安的是,用我们的数据训练出来的 AI,未来可能还会取代我们的工作。尽管 AI 也可能创造新的就业机会,但这种数据垄断带来的财富集中效应,无疑加剧了社会的不平等。我们似乎正在滑向一个由少数科技巨头控制的赛博朋克世界。
那么,作为普通人,我们该如何在这个 AI 时代保护自己的利益?AI 兴起之后,很多人将区块链视为人类抵抗 AI 的最后一道防线。正是基于这样的思考,一些创新者开始探索解决方案。他们提出:首先,我们要夺回对自己数据的所有权和控制权;其次,我们要利用这些数据,共同训练一个真正为普通人服务的 AI 模型。
这个想法看似理想主义,但历史告诉我们,每一次技术革命都始于一个「疯狂」的构想。而今天,一个名为「Vana」的全新公链项目正在将这个构想变为现实。作为首个去中心化数据流动性网络,Vana 试图让你的数据转化为可自由流通的代币,并以此推动实现真正由用户掌控的去中心化人工智能。
Vana 的创始人与项目源起
事实上,Vana 的诞生可以追溯到麻省理工学院(MIT)媒体实验室的一间教室。在那里,两位怀揣改变世界理想的年轻人——Anna Kazlauskas 和 Art Abal——相遇了。

左:Anna Kazlauskas;右:Art Abal
Anna Kazlauskas 在 MIT 主修计算机科学和经济学,她对数据和加密货币的兴趣可以追溯到 2015 年。那时的她正在参与以太坊的早期挖矿,这段经历让她深刻认识到去中心化技术的潜力。随后,Anna 在美联储、欧洲央行和世界银行等国际金融机构进行数据研究,这些经历让她意识到在未来的世界里,数据将成为一种新的货币形式。
与此同时,Art Abal 在哈佛大学攻读公共政策硕士学位,并在贝尔福科学与国际事务中心深入研究数据影响评估。在加入 Vana 之前,Art 在 AI 训练数据提供商 Appen 公司主导了创新的数据收集方法,这些方法为当今许多生成式 AI 工具的诞生做出了重要贡献。他在数据伦理和 AI 责任方面的洞察,为 Vana 注入了强烈的社会责任感。
当 Anna 和 Art 在 MIT 媒体实验室的课程中相遇时,他们很快发现彼此对数据民主化和用户数据权益有着共同的热忱。他们意识到,要真正解决数据所有权和 AI 公平性的问题,需要一个全新的范式——一个能够让用户真正掌控自己数据的系统。
正是这种共同的愿景,促使他们携手创立了 Vana。他们的目标是打造一个革命性的平台,不仅要为用户争取数据主权,还要确保用户能从自己的数据中获得经济利益。通过创新的 DLP(Data Liquidity Pool)机制和贡献证明(Proof of Contribution)系统,Vana 让用户能够安全地贡献私有数据,共同拥有并受益于由这些数据训练出的 AI 模型,从而推动用户主导的 AI 发展。
Vana 的愿景迅速得到了业界的认可。截止目前,Vana 宣布已经完成了总计 2500 万美元的融资,其中包括由 Coinbase Ventures 领投的 500 万美元战略轮融资、Paradigm 领投的 1800 万美元 A 轮融资,以及 Polychain 领投的 200 万美元种子轮融资。其他知名投资者还包括 Casey Caruso、Packy McCormick、Manifold、GSR、DeFiance Capital 等。
在这个数据就是新时代石油的世界里,Vana 的出现,无疑为我们提供了一个夺回数据主权的重要机会。那么,这个充满潜力的项目究竟是如何运作的?让我们一起来深入了解 Vana 的技术架构和创新理念。
Vana 的技术架构和创新理念
Vana 的技术架构堪称一个精心设计的生态系统,旨在实现数据的民主化和价值最大化。其核心组成部分包括数据流动性池(DLP)、贡献证明机制、名古屋共识、用户自托管数据以及去中心化应用层。这些元素共同构建了一个既能保护用户隐私,又能释放数据潜在价值的创新平台。
1. 数据流动性池(DLP):数据价值化的基石
数据流动性池是 Vana 网络的基本单位,可以将其理解为数据版的「流动性挖矿」。每个 DLP 本质上是一个智能合约,专门用于聚合特定类型的数据资产。例如,Reddit 数据 DAO(r/datadao)就是一个成功的 DLP 案例,吸引了超过 14 万 Reddit 用户加入。它聚合了用户的 Reddit 帖子、评论和投票历史。

用户向 DLP 提交数据后,可以获得该 DLP 特定的代币奖励,比如 Reddit 数据 DAO(r/datadao)的特定代币就是 RDAT。这些代币不仅代表了用户对数据池的贡献,还赋予了用户对 DLP 的治理权和未来收益分配的权利。值得注意的是,Vana 允许每个 DLP 发行自己的代币,这为不同类型的数据资产提供了更灵活的价值捕获机制。
在 Vana 的生态系统中,排名前 16 的 DLP 还能获得额外的 VANA 代币排放奖励,这进一步刺激了高质量数据池的形成和竞争。通过这种方式,Vana 巧妙地将零散的个人数据转化为具有流动性的数字资产,为数据的价值化和流动性奠定了基础。
2. 贡献证明(Proof of Contribution):数据价值的精确度量
贡献证明是 Vana 确保数据质量的关键机制。每个 DLP 都可以根据自身特点,定制独特的贡献证明函数。这个函数不仅验证数据的真实性和完整性,还评估数据对 AI 模型性能提升的贡献度。
以 ChatGPT 数据 DAO 为例,其贡献证明涵盖了四个关键维度:真实性、所有权、质量和独特性。真实性通过验证 OpenAI 提供的数据导出链接链接来确保;所有权则通过用户的邮箱验证;质量评估则借助 LLM 对随机抽样的对话进行打分;独特性则通过计算数据的特征向量并与现有数据比对来确定。
这种多维度的评估确保了只有高质量、有价值的数据才能被接受并获得奖励。贡献证明不仅是数据定价的基础,也是维护整个生态系统数据质量的关键保障。
3. 名古屋共识(Nagoya Consensus):去中心化的数据质量保证
名古屋共识是 Vana 网络的心脏,它借鉴并改进了 Bittensor 的尤马共识(Yuma Consensus)。这一机制的核心思想是通过一群验证节点对数据质量进行集体评估,采用加权平均的方式得出最终分数。
更具创新性的是,验证节点不仅要评估数据,还要对其他验证节点的评分行为进行打分。这种「双层评估」机制极大地提高了系统的公平性和准确性。例如,如果一个验证节点给一份明显低质量的数据打了高分,其他节点会对这一不当行为作出惩罚性评分。
每隔 1800 个区块(约 3 小时)为一个周期,系统会根据这一期间的综合评分,向验证节点分配相应的奖励。这种机制不仅激励了验证节点保持诚实,还能迅速识别和淘汰不良行为,从而维护整个网络的健康运行。
4. 非托管数据存储:隐私保护的最后一道防线
Vana 的一大创新在于其独特的数据管理方式。在 Vana 网络中,用户的原始数据从未真正「上链」,而是由用户自行选择存储位置,比如 Google Drive、Dropbox,乃至在 Macbook 上运行的个人服务器。
当用户向 DLP 提交数据时,他们实际上只是提供了指向加密数据的 URL 和一个可选的内容完整性哈希。这些信息被记录在 Vana 的数据注册合约中。验证者在需要访问数据时,会请求解密密钥,然后下载并解密数据进行验证。
这种设计巧妙地解决了数据隐私和控制权的问题。用户始终保持对自己数据的完全控制,同时又能参与到数据经济中。这不仅确保了数据的安全性,还为未来更广泛的数据应用场景提供了可能。
5. 去中心化应用层:数据价值的多元化实现
Vana 的顶层是一个开放的应用生态系统。在这里,开发者可以利用 DLP 积累的数据流动性构建各种创新应用,而数据贡献者则可以从这些应用中获得实际的经济价值。
例如,一个开发团队可能会基于 Reddit 数据 DAO 的数据训练一个专门的 AI 模型。参与数据贡献的用户不仅可以在模型训练完成后使用它,还可以按照各自的贡献比例获得模型产生的收益。实际上这样的 AI 模型已经开发出来了,详情可阅读《触底反弹,AI 赛道老币 r/datadao 为何起死回生?》。
这种模式不仅激励了更多高质量数据的贡献,还创造了一个真正由用户主导的 AI 开发生态系统。用户从单纯的数据提供者,转变为 AI 产品的共同所有者和受益者。
通过这种方式,Vana 正在重塑数据经济的格局。在这个新的范式中,用户从被动的数据提供者转变为积极参与、共同受益的生态系统建设者。这不仅为个人创造了新的价值获取渠道,也为整个 AI 行业注入了新的活力和创新动力。
Vana 的技术架构不仅解决了当前数据经济中的核心问题,如数据所有权、隐私保护和价值分配,还为未来的数据驱动创新铺平了道路。随着更多的数据 DAO 加入网络,更多的应用在平台上构建,Vana 有潜力成为下一代去中心化 AI 和数据经济的基础设施。
Satori 测试网:Vana 的公开测试场
随着 Satori 测试网于 6 月 11 日的推出,Vana 向公众展示了其生态系统的雏形。这不仅是技术验证的平台,更是未来主网运行模式的预演。目前,Vana 生态为参与者提供了三条主要路径:运行 DLP 验证节点、创建新的 DLP,或者向现有 DLP 提交数据参与「数据挖矿」。
运行 DLP 验证节点
验证节点是 Vana 网络的守门人,负责验证提交到 DLP 的数据质量。运行验证节点不仅需要技术能力,还需要足够的计算资源。根据 Vana 的技术文档,验证节点的最低硬件要求为 1 个 CPU 核心、8GB RAM 和 10GB 高速 SSD 存储空间。
有意成为验证者的用户需要先选择一个 DLP,然后通过该 DLP 的智能合约注册成为验证者。一旦注册获得批准,验证者就可以运行特定于该 DLP 的验证节点。值得注意的是,验证者可以同时为多个 DLP 运行节点,但每个 DLP 都有其独特的最低质押要求。
创建新的 DLP
对于那些有独特数据资源或创新想法的用户,创建新的 DLP 是一个极具吸引力的选择。创建 DLP 需要深入理解 Vana 的技术架构,特别是贡献证明和名古屋共识机制。
新 DLP 的创建者需要设计特定的数据贡献目标、验证方法和奖励参数。同时,他们还需要实现一个能准确评估数据价值的贡献证明函数。这个过程虽然复杂,但 Vana 提供了详细的模板和文档支持。
参与数据挖矿
对于大多数用户来说,向现有 DLP 提交数据参与「数据挖矿」可能是最直接的参与方式。目前,已经有 13 个 DLP 得到了官方推荐,涵盖了从社交媒体数据到金融预测数据的多个领域。
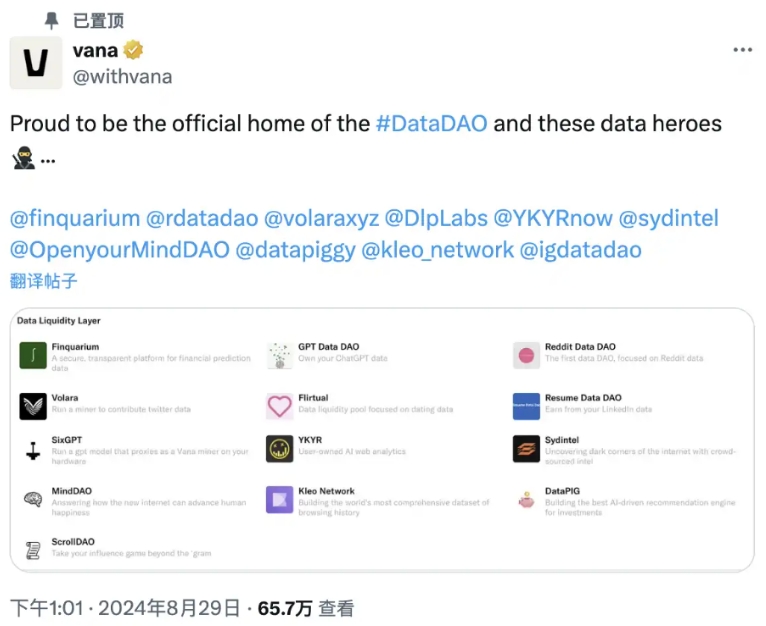
· Finquarium:汇集金融预测数据。
· GPT Data DAO:专注于 ChatGPT 聊天数据导出。
· Reddit Data DAO:聚焦 Reddit 用户数据,已正式启动。
· Volara:专注于 Twitter 数据的收集和利用。
· Flirtual:收集约会数据。
· ResumeDataDAO:专注于 LinkedIn 数据导出。
· SixGPT:收集和管理 LLM 聊天数据。
· YKYR:收集 Google Analytics 数据。
· Sydintel:通过众包智能揭示互联网的黑暗角落。
· MindDAO:收集用户幸福感相关的时间序列数据。
· Kleo:构建全球最全面的浏览历史数据集。
· DataPIG:关注代币投资偏好数据。
· ScrollDAO:收集和利用 Instagram 数据。
这些 DLP 有的还在开发,有的已经上线,但是都处于预挖矿阶段。因为只有等主网上线之后,用户才能正式提交数据进行挖矿。不过,用户现在可以通过多种方式提前锁定参与资格。例如,用户可以参与Vana Telegram App中的相关挑战活动,或者在各个 DLP 的官方网站上进行预注册。
总结
Vana 的出现,标志着数据经济正在迎来一场范式转变。在当前 AI 浪潮中,数据已然成为新时代的「石油」,而 Vana 则试图重塑这一资源的开采、精炼和分配模式。
本质上,Vana 正在构建一个数据版的「公地悲剧」解决方案。通过巧妙的激励设计和技术创新,它使得个人数据这一看似无限供给却难以变现的资源,转变为一种可管理、可定价、可流通的数字资产。这不仅为普通用户参与 AI 红利分配开辟了新途径,更为去中心化 AI 的发展提供了一个可能的蓝图。
然而,Vana 的成功仍面临诸多不确定性。技术上,它需要在开放性和安全性之间寻找平衡;经济上,它需要证明其模式能够产生持续的价值;社会层面,它还需应对潜在的数据伦理和监管挑战。
更深层次来看,Vana 代表了一种对现有数据垄断和 AI 发展模式的反思与挑战。它提出了一个重要问题:在 AI 时代,我们是选择继续强化现有的数据寡头,还是尝试构建一个更加开放、公平、多元的数据生态?
无论 Vana 最终能否成功,它的出现都为我们提供了一个重新思考数据价值、AI 伦理和技术创新的窗口。在未来,类似 Vana 这样的项目或许会成为连接 Web3 理想与 AI 现实的重要桥梁,为数字经济的下一阶段发展指明方向。
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐

Supra网络在共享安全平台上提供了广泛的服务和功能,包括创新的分布式预言机协议(DORA)、原生垂直整合结构、分布式可验证随机函数(DVRF)、零区块延迟自动化网络、受AppChain启发的容器、MultiVM支持以及通过并行交易处理优化的区块执行。此外,还有桥接设计——HyperLoop和HyperNova——使Supra成为全球首个“IntraLaye...

Zircuit 是一个创新的 Layer 2 区块链网络,结合了 Zk-Rollup 和 Optimistic Rollups 的混合架构,目标是提供高效、安全、低成本的解决方案。它与以太坊虚拟机(EVM)兼容,允许开发者轻松迁移现有的以太坊应用,并享受更高的交易吞吐量和更低的费用。Zircuit 还引入了独特的链上安全系统,通过序列器级安全性和自动化 AI 机...

智能合约通过区块链网络中的自执行代码,实现了安全和自动化的交易。它们简化了协议流程,省去了中介和人工干预。本文将探讨智能合约的工作机制、实际应用以及在传统系统中面临的挑战。关键要点智能合约能够自动化并保障数字协议的安全性。这些数字合约不再需要中介,从而实现更快、更可靠的交易。金融、供应链和房地产等多...
社区")
区块链的最大特性之一就是去中心化的概念,这是指将权力、决策和其他资源从单一的中心实体分配给多个实体的过程。该概念已经彻底改变了多个行业,包括金融(DeFi)、加密货币交易(通过去中心化交易所 DEX)甚至科学研究(称为去中心化科学DeSci)。尤其是在 DeSci 领域,区块链技术和去中心化系统被用来资助、开展和分享科...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图

