在过去几周里,我们一直在发布内容来解释 Grass 在 AI 堆栈中的作用。Grass 协议执行多项功能,帮助开发人员访问网络数据来训练他们的模型,这是 AI 管道的关键第一阶段,也是所有开发的起点。
Grass 的独特之处
在 Grass 的案例中,全球各地的家用设备都托管着一个节点网络,这些节点从网络上抓取和处理原始数据。这些数据经过清洗和结构化,形成用于 AI 训练的数据集。更重要的是,Grass 以一种让全球近百万人参与并得到奖励的方式获取网络数据,独自创建了 AI 数据供应类别,这也是世界上一些最大的 AI 公司选择与我们合作的原因。
当前人工智能的挑战
与此同时,我们也一直在反思人工智能的现状。我们问自己,人工智能面临的最紧迫的问题是什么,作为人工智能基础设施的重要组成部分,我们可以做些什么来解决这些问题。
我们的结论是,目前人工智能最大的问题是缺乏数据透明度。新闻报道中经常出现 AI 模型出错的情况,比如将伊隆·马斯克和希特勒等同起来,或者从世界历史中抹去整个民族。这些错误可能是由于使用了不良数据训练模型,或者是用有选择地选择的好数据给出了错误的答案。然而,我们无法确定这些模型是用什么数据训练的,因为没有机制可以证明这一点。用户无法验证数据来源,因为构建者自己也无法验证。
解决方案:数据汇总
为了解决这个问题,Grass 正在构建数据汇总来验证数据来源。每次 Grass 节点抓取数据时,都会记录元数据以验证数据是从哪个网站抓取的。这些元数据将永久嵌入到每个数据集中,使构建者能够完全确定其来源。然后,他们可以与用户分享这一谱系,用户就可以放心,因为他们知道与之交互的 AI 模型不是故意训练来给出误导性答案的。
数据汇总的设计
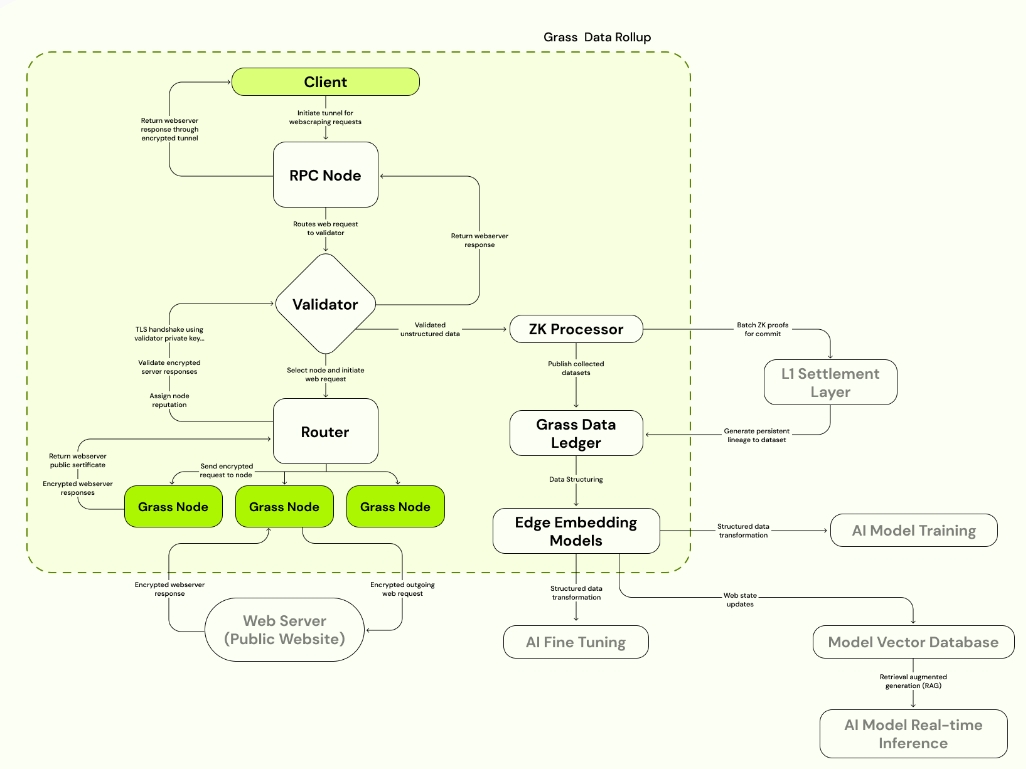
理解这些升级的最简单方法是查阅 Grass 数据汇总图。在左侧,您可以看到 Grass 的传统网络定义,客户端发出 Web 请求,这些请求通过验证器发送,最终通过 Grass 节点路由。无论客户端请求哪个网站,其服务器都会响应 Web 请求,允许其数据被抓取并发送回线路。然后,数据将被清洗、处理并准备用于训练下一代 AI 模型。
在右侧,您会看到两个主要的新增内容,它们将伴随 Grass 主权数据汇总的推出:Grass 数据分类账和 ZK 处理器。
Grass 数据分类账
Grass 数据分类账是所有数据的最终存储地。它是 Grass 上抓取的每个数据集的永久账本,现在嵌入了元数据,以记录其从起源时刻开始的谱系。每个数据集的元数据证明将存储在 Solana 的结算层上,结算数据本身也将通过账本提供。重要的是,Grass 需要一个地方来存储它抓取的数据。
ZK 处理器
ZK 处理器的目的是协助记录 Grass 网络上抓取的数据集的来源。当网络上的节点向给定网站发送 Web 请求时,它会返回一个加密响应,其中包含节点请求的所有数据。这正是数据集诞生的时刻,也是需要记录的起源时刻。
ZK 处理器记录的元数据包含许多字段,如会话密钥、被抓取网站的 URL、目标网站的 IP 地址、交易的时间戳,当然还有数据本身。这些信息可以毫无疑问地证明给定的数据集来自它声称的网站,从而确保 AI 模型得到了正确且忠实的训练。
ZK 处理器之所以重要,是因为这些数据需要在链上结算,但我们不希望 Solana 验证器看到所有这些数据。此外,未来在 Grass 上执行的大量 Web 请求将不可避免地超过任何 L1 的吞吐量。Grass 将扩展到每分钟执行数千万个 Web 请求的程度,每个请求的元数据都需要在链上结算。如果没有 ZK 处理器先进行证明和批处理,就不可能将这些交易提交给 L1。因此,rollup 是实现我们目标的唯一可能方法。
数据汇总的好处
数据分类账
数据分类账的意义在于它将 Grass 的扩张升级为一种额外的、根本不同的商业模式。虽然该协议将继续审查发送自己的网络请求并在网络上抓取自己的数据的买家,但其越来越多的活动将涉及已经存储在账本上的数据。凭借这一功能,Grass 现在可以抓取经过战略性策划以用于 LLM 培训的数据,并将其托管在不断扩大的数据存储库中。
ZK 处理器
我们已经详细介绍了 ZK 处理器的重要性。通过使我们能够创建记录 Grass 数据集来源的元数据证明,它为构建者和用户创建了一种机制,可以验证 AI 模型是否得到了正确的训练。这本身就是一件大事。
然而,还有一个我们之前没有提到的部分。元数据不仅记录了数据集来源的网站,还指示数据集通过了网络上的哪个节点。这意味着每当一个节点抓取网络数据时,他们都可以因其工作而获得荣誉,而无需透露任何有关他们自己的身份信息。
这很重要,因为一旦能证明哪些节点完成了哪些工作,就可以开始按比例奖励它们。有些节点比其他节点更有价值,有些节点比同类节点抓取的数据更多。这些正是我们需要激励的节点,以继续我们在过去几个月看到的网络的快速扩张。我们相信,这种机制将显著提高全球最受欢迎地区的奖励,最终鼓励这些地区的人们注册并成倍增加网络的容量。
结论
总之,当今人工智能的大多数突出问题都源于对模型训练方式缺乏了解。我们相信,通过为开源人工智能提供数据来源验证系统,可以解决这个问题。我们的解决方案是构建第一个数据汇总,这将使引入一种记录所有数据集来源的元数据的机制成为可能。这些数据的零知识证明将存储在 L1 结算层上,元数据本身最终将与其底层数据集绑定,因为这些数据集本身存储在我们自己的数据分类账上。因此,零知识证明为提高透明度和为节点提供商提供与其执行的工作量成比例的奖励奠定了基础。
网址:https://www.getgrass.io/
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐
社区")
区块链的最大特性之一就是去中心化的概念,这是指将权力、决策和其他资源从单一的中心实体分配给多个实体的过程。该概念已经彻底改变了多个行业,包括金融(DeFi)、加密货币交易(通过去中心化交易所 DEX)甚至科学研究(称为去中心化科学DeSci)。尤其是在 DeSci 领域,区块链技术和去中心化系统被用来资助、开展和分享科...

Reef Finance 是一个全球性的流动性聚合器和多链智能收益引擎,能够无缝地与其他 De-Fi 应用互动。它拥有 Reef Yield Engine,这是一款帮助智能借贷、挖矿、质押以及其他活动的收益引擎,并融合了 AI 技术的强大功能。Reef Chain 与以太坊虚拟机(EVM)兼容,允许开发者轻松将以太坊构建的协议迁移到 Reef Chain,并托管他们...

Nektar Network 是一个去中心化的流动性与基础设施市场,旨在通过去中心化资产管理者(DAMs)连接区块链生态系统中的利益相关方,包括委托人、运营商、网络和管理者。该平台通过去中心化经济连接各方,能够高效聚合流动性、优化基础设施使用,并实施定制化奖励方案。它允许资产的安全高效委托,使网络参与者能够扩展其运营,...

Cryowar(CWAR)是一款基于Solana构建的实时多人PVP竞技场NFT游戏。它结合了区块链技术与技能战斗,可为用户提供沉浸式的游戏体验。随着新兴技术颠覆游戏的玩法和盈利模式,游戏行业正迎来显著增长。区块链技术的引入让玩家能更多地控制游戏资产,去中心化生态系统也为玩家主导的经济体创造了新机会。随着向 Web3 和去中心化...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图

