作者介绍
第一作者及通信作者:徐明辉
徐明辉于2018年在北京师范大学获得物理学学士学位,2021年在美国华盛顿特区乔治华盛顿大学获得计算机科学博士学位。现任山东大学计算机科学与技术学院副教授。他的研究重点是区块链、分布式计算和应用密码学。
介绍
去中心化学习涉及通过远程移动设备、边缘服务器或云服务器训练机器学习模型,同时保持数据本地化。尽管许多研究表明了保护隐私、提高训练性能或引入拜占庭弹性的可行性,但没有一个研究同时考虑这些。因此现有研究面临以下问题:如何高效协调去中心化学习过程,同时维护整个系统的学习安全和数据隐私?
为了解决这个问题,本文提出了 SPDL:一个基于区块链安全且保护隐私的去中心化学习系统。SPDL将区块链、拜占庭容错(BFT)共识、BFT梯度聚合规则(GAR)和差分隐私无缝集成到一个系统中,确保高效的机器学习,同时保护数据隐私、拜占庭容错、透明度和可追溯性。为了验证所提出的方法,本文对存在拜占庭节点的情况下的收敛和遗憾进行了严格的分析。文章还构建了 SPDL 原型并进行了广泛的实验,以证明 SPDL 是有效且高效的,并具有强大的安全性和隐私保证。
动机
去中心化学习面临以下挑战:如何有效协调去中心化学习过程,同时维护整个系统的学习安全和数据隐私?
具体为以下3点:
1、如果没有完全信任的中心化托管者,由于对去中心化网络缺乏信任,用户没有动力也不愿意参与学习过程。因此,数据量很可能不足以训练可靠的模型。
2、在去中心化学习中,可以进行任意行为(例如崩溃或发起攻击)的拜占庭节点可能会阻止模型收敛或中断训练过程。
3、在隐私与安全以及效率之间进行权衡,并在保证隐私和透明度的情况下使数据共享无障碍,是具有挑战性的。
贡献
1、SPDL是第一个用于去中心化网络的安全且保护隐私的机器学习系统,其中学习过程不受可信参数服务器的影响。
2、SPDL利用DP进行数据隐私保护,将BFT共识和BFT GAR无缝嵌入到区块链系统中,在保持高效率的同时,有利于具有拜占庭容错、透明和可追溯性的模型训练。
3、本文在拜占庭节点存在的情况下对 SPDL 进行了严格的收敛和遗憾分析,构建了SPDL原型,并进行了大量的实验来证明 SPDL 的可行性和有效性。
系统设计
设计目标
1)去中心化:SPDL应该在去中心化的网络设置中工作,而无需任何中心化方(例如参数服务器)的干预。
2)差分隐私:SPDL应该通过添加随机高斯噪声扰乱梯度来保证(𝜖,ð)-DP。文章的目标是在隐私泄露和收敛速度之间达到平衡。
3)拜占庭容错:SPDL可以确保收敛到最多f(N = 3f+1)个可以进行任意行为的拜占庭节点。
4)不可变性、透明性和可追溯性:机器学习过程的完整记录应该是不可变和透明的,并提供可追溯性,以实现拜占庭节点检测。
SPDL工作流程
A、初始工作
Step1:每个节点创建一对私钥sk和公钥pk,并根据pk生成其唯一的256位身份id。
Step2:节点广播pk和id。
Step3:创建创世块B0,记录新参与区块链网络的节点的信息。新加入的节点在加入许可网络之前应该有一个相关的交易tx添加到区块链中,其中 tx 包含必要的信息,包括其 pk、id和IP地址。
Step4:每个节点拥有相同信誉值,学习率,总轮数,高斯噪声方差。
B、领导者选举
每个节点执行算法1所示的领导者选举算法。该算法基于可验证随机函数(VRF),以私钥sk和随机种子作为输入,输出哈希字符串h以及相应的证明π。每个竞争者都广播 (hi,πi) 到网络并接收来自peer的(h,π)。同时,每个节点都分配有一个信誉变量r∈[0,1]。信誉ri = 0的节点 i 禁止成为领导者。π最大且r > 0的节点被认定为负责区块链共识的领导者。如果采用常用的 SHA-256,π的空间很大,为 2256,因此选择多个领导者的情况极小;但如果发生这种极端情况,所有节点都会重新启动领导者选举过程,以确保最终只选择一个领导者。本文还为领导者选举过程设置了一个超时时间 Time() >start + ð1,其中Time()提取当前的 UNIX 时间。
总而言之,领导者选举算法实现了以下三个基本功能:
信誉值为零的节点无权成为领导者。
领导者选举过程具有完全随机性和不可预测性。
拜占庭节点无法将自己伪装成领导者。

C、梯度计算
如算法2所示,整个交换过程可以概括为以下步骤:
局部梯度计算:计算局部随机梯度。
添加噪声:将随机高斯噪声添加到要共享的局部梯度中。噪声的方差由输入变量σ表示。
广播梯度:将扰动的局部梯度发送给所有其他节点,同时接收其他节点的梯度。

D、区块链共识
区块链共识过程深度集成了区块链、BFT共识协议和BFT聚合函数(例如Krum、Median)。本文中采用实用拜占庭容错(PBFT)协议作为共识主干。区块链共识中使用的聚合规则是Krum。区块链共识步骤如算法3所示。

具体来说,区块链共识包括四个阶段:PRE-PREPARE、PREPARE、COMMIT、DECIDE。
1)PRE-PREPARE:
在 PRE-PREPARE 阶段,领导者使用聚合函数计算聚合梯度△(t)。Krum的核心思想是消除与其他梯度相差太远的梯度。本文使用欧几里得距离来测量两个梯度分开的距离。near(i)定义为最接近n-f-2个梯度的集合。Krum函数需要选择一个与其周围梯度最接近的梯度 gi(t)。更准确地说,Krum 的输出是其输入梯度之一,该梯度的索引为:

2)PREPARE:
每个follower需基于其局部扰动梯度计算自己的聚合梯度,然后等待pre-prepare消息。如果收到pre-prepare消息,follower首先验证数字签名σ和区块(高度、区块哈希等)。然后将自己和leader的聚合梯度进行比较。如果验证通过,follower广播一条prepare消息。
3)COMMIT:
在 COMMIT 阶段,如果节点收到 2f + 1 条有效提交消息,则可以广播commit消息,并进入接下来的DECIDE阶段。
4)DECIDE:
在 DECIDE 阶段,节点在收到 2f + 1 条有效提交消息后,可以将新块 Bk(t) 附加到其本地区块链BCk,同时更新其本地梯度和信誉。如果某个节点 i 的梯度偏离聚合梯度超过 π/2,则该节点的信誉可能会降低。为了避免死锁的发生,本文在区块链共识过程中设置了超时时间。如果Time() > start + ð2,则每个节点广播视图改变VIEW CHANGE消息并等待其他peer的回应。当收到 2f + 1 条视图改变消息时,节点可以放弃当前回合。
实验
实验配置:
SPDL采用gRPC框架、底层通信的P2P网络、机器学习库的Pytorch以及具有PBFT共识算法的区块链系统。在 SPDL 中,节点通过使用 ECDSA 生成密钥对、初始化创世块、建立 gRPC 连接、交换节点列表以及加入 P2P 网络进行引导。
数据集:
MNIST:由 10 个类别的 70,000 张 28×28 幅图像的手写数字组成。数据集被平均分为 N 组,每组分配给一个节点。
评估标准:
1、Test Error(测试误差):使用测试数据集,所有预测中错误预测的比例。实验根据轮次、网络大小、批量大小、隐私预算和拜占庭比率来衡量测试误差。
2、Latency(延迟):每轮的延迟。
对比实验:
PURE:去中心化学习
DP:去中心化学习+DP高斯噪声
SPDL:去中心化学习+ DP高斯噪声+BFT聚合规则+区块链,即本文的方案
A、网络规模
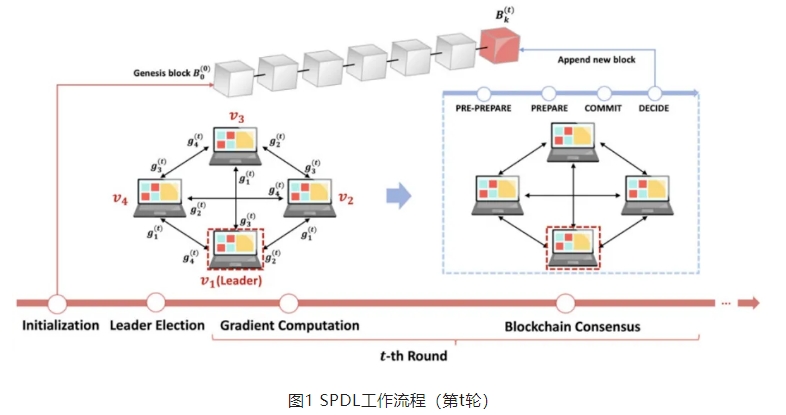
如图3所示,20轮次后测试误差基本收敛,但当N小到4时,测试误差波动很大。当 N = 30 时,所有方案几乎达到相同的收敛性。N = 20 或 N = 30时,SPDL 和 DP 方案的测试误差低于 PURE,因为添加噪声可能会防止训练过程过度拟合。此外,网络规模并不影响收敛速度,网络规模大有助于稳定收敛。
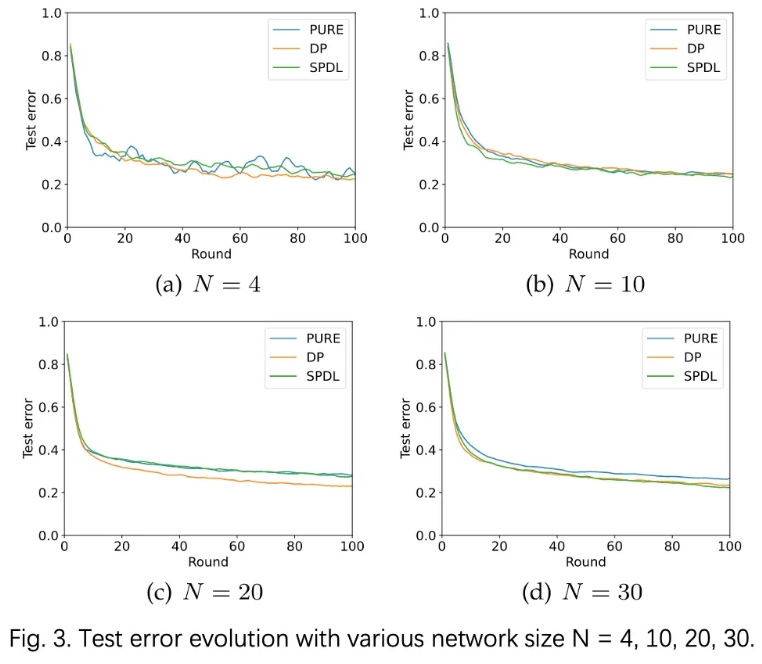
B、延迟
TLGC:本地梯度计算+添加噪声
TGE :梯度交换
TBC :区块链共识
图4所示,TLGC、TGE和TBC处于同一数量级。TGE 随着 N 的增长而增长,仅仅是因为更多的节点争夺计算资源。MNIST分类任务可以快速完成(< 0.1 s/轮),因此在实验中 TLGC 低于 TBC。当机器学习任务变得更加困难时(例如,10 分钟/轮),TBC 1秒是可以接受的开销,甚至可以忽略。
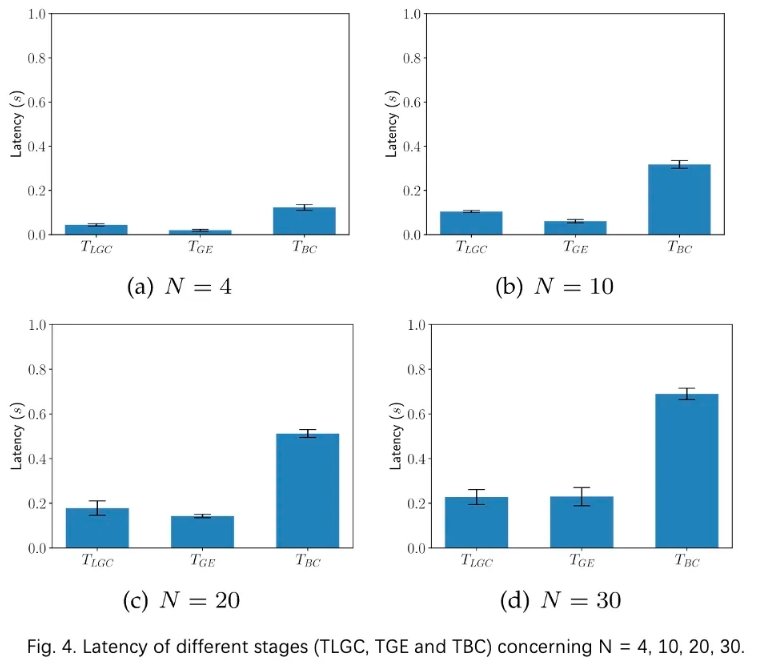
C、拜占庭节点存在下的收敛性
图5所示,在非拜占庭实验的结果下,三种方案都能达到相似的收敛性。然而,DP和PURE方案在BR > 0%时测试误差较高,即使存在10%N拜占庭节点也无法保证模型收敛。图5清楚地表明,对于不同级别的拜占庭攻击,SPDL 仍然可以实现相同的收敛。
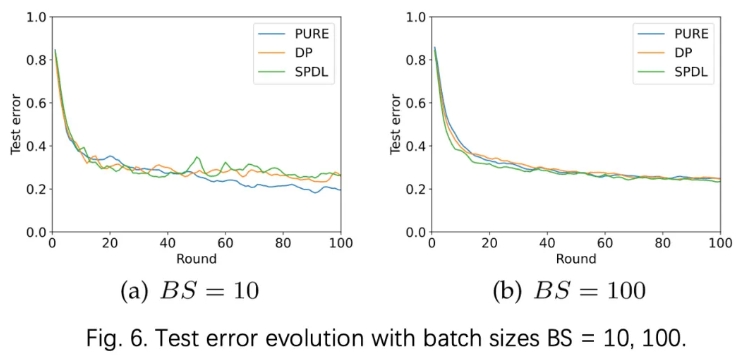
D、批量大小:BS
图6表明,当 BS = 10 时,所有部署中的测试误差波动很大。PURE 方案优于其他方案是因为添加噪声会扰乱模型收敛。然而,图 6b 表明可以增加批量大小以确保稳定的收敛并使本文的 SPDL 作为 PURE 方案表现良好。
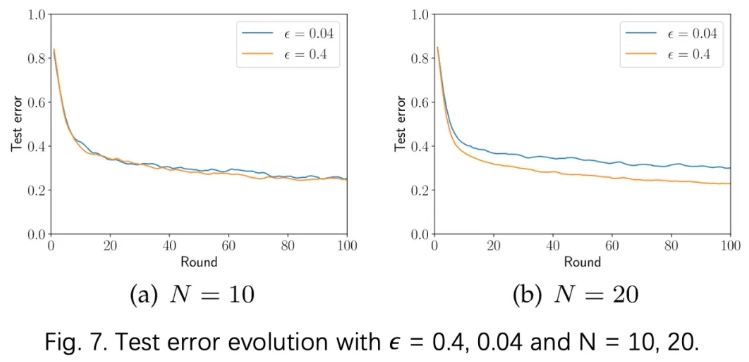
E、差分隐私参数策略:𝜖
图7表明,当 N = 10 时,𝜖 = 0.4 或 0.04 添加噪声具有相似的收敛性。但当N = 20时,较小的值会导致较大的测试误差。这意味着应根据隐私保护和模型准确性的具体要求仔细调整准确性和隐私保护之间的权衡。
总结
SPDL是一种新颖的去中心化机器学习系统,可以在保证效率的同时实现强有力的安全和隐私保障。特别是,SPDL利用BFT共识和BFT GAR来保护模型更新免受严酷的拜占庭行为的影响,利用区块链发挥透明性和可追溯性的优势,并采用DP技术进行隐私保护。本文对SPDL的有效性进行了严格的理论分析,并对 SPDL 的性能随网络大小、批量大小、隐私预算和拜占庭比率的变化进行了广泛的研究。
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐
社区")
区块链的最大特性之一就是去中心化的概念,这是指将权力、决策和其他资源从单一的中心实体分配给多个实体的过程。该概念已经彻底改变了多个行业,包括金融(DeFi)、加密货币交易(通过去中心化交易所 DEX)甚至科学研究(称为去中心化科学DeSci)。尤其是在 DeSci 领域,区块链技术和去中心化系统被用来资助、开展和分享科...

Reef Finance 是一个全球性的流动性聚合器和多链智能收益引擎,能够无缝地与其他 De-Fi 应用互动。它拥有 Reef Yield Engine,这是一款帮助智能借贷、挖矿、质押以及其他活动的收益引擎,并融合了 AI 技术的强大功能。Reef Chain 与以太坊虚拟机(EVM)兼容,允许开发者轻松将以太坊构建的协议迁移到 Reef Chain,并托管他们...

Nektar Network 是一个去中心化的流动性与基础设施市场,旨在通过去中心化资产管理者(DAMs)连接区块链生态系统中的利益相关方,包括委托人、运营商、网络和管理者。该平台通过去中心化经济连接各方,能够高效聚合流动性、优化基础设施使用,并实施定制化奖励方案。它允许资产的安全高效委托,使网络参与者能够扩展其运营,...

Cryowar(CWAR)是一款基于Solana构建的实时多人PVP竞技场NFT游戏。它结合了区块链技术与技能战斗,可为用户提供沉浸式的游戏体验。随着新兴技术颠覆游戏的玩法和盈利模式,游戏行业正迎来显著增长。区块链技术的引入让玩家能更多地控制游戏资产,去中心化生态系统也为玩家主导的经济体创造了新机会。随着向 Web3 和去中心化...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图

