最早的决策树算法是由Hunt等人于1966年提出,Hunt算法是许多决策树算法的基础,包括ID3、C4.5和CART等。
决策树算法是一种有监督学习算法,利用分类的思想,根据数据的特征构建数学模型,从而达到数据的筛选,决策的目标。
01 决策树简介
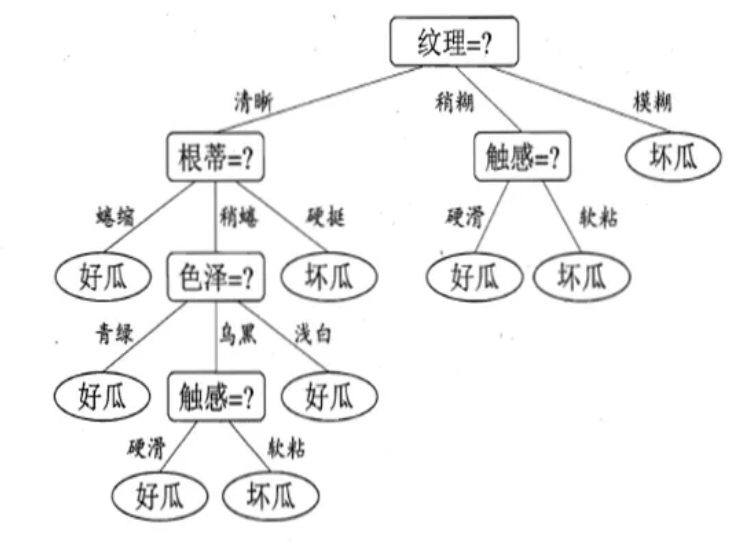
决策树是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模型,每一条从根结点(对最终分类结果贡献最大的属性)到叶子结点(最终分类结果)的路径都代表一条决策的规则。决策树就是形如下图的结构:
02 基本流程
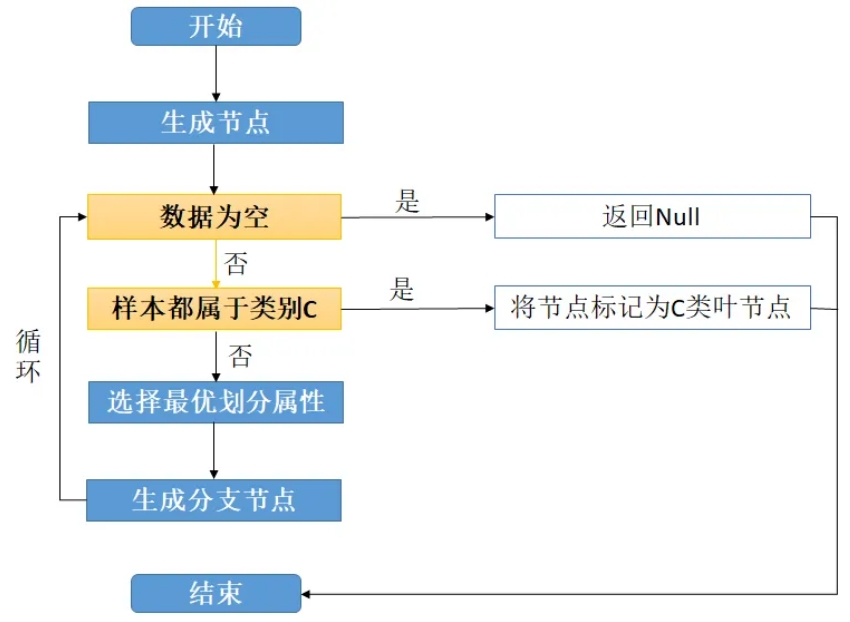
①首先从开始位置,将所有数据划分到一个节点,即根节点。
②然后经历黄色的两个步骤,黄色的表示判断条件:
若数据为空集,跳出循环。如果该节点是根节点,返回null;如果该节点是中间节点,将该节点标记为训练数据中类别最多的类;
若样本都属于同一类,跳出循环,节点标记为该类别。
③如果经过黄色标记的判断条件都没有跳出循环,则考虑对该节点进行划分。既然是算法,则不能随意的进行划分,要讲究效率和精度,选择当前条件下的最优属性划分。
④经历上步骤划分后,生成新的节点,然后循环判断条件,不断生成新的分支节点,直到所有节点都跳出循环。
⑤结束。这样便会生成一棵决策树。
03 划分选择
熵:物理意义是体系混乱程度的度量。
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小。
信息增益
假设训练数据集D和特征A,根据如下步骤计算信息增益:
第一步:计算数据集D的经验熵:

般而言,信息增益越大,则意味着使用属性A来进行划分所获得的“纯度提升” 越大。因此,我们可使用信息增益来进行决策树的划分属性选择。ID3决策树学习算法就是以信息增益为准则来选择划分属性的。
信息增益率
特征A对于数据集D的信息增益比在此定义为:
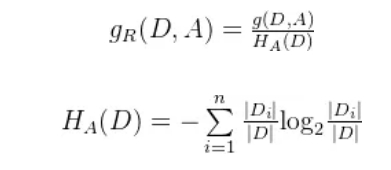
其中,HA(D)称为数据集D关于A的取值熵。
增益率准则就可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
基尼指数
分类问题中,假设有K个类,样本点属于k的概率pk,则概率分布的基尼指数:

CART决策树使用“基尼指数”来选择划分属性。数据集D的纯度可用基尼值来度量,Gini(D)越小,则数据集的纯度越高。CART生成的是二叉树,计算量相对来说不是很大,可以处理连续和离散变量,能够对缺失值进行处理。
04 剪枝处理
剪枝:顾名思义就是给决策树 "去掉" 一些判断分支,同时在剩下的树结构下仍然能得到不错的结果。之所以进行剪枝,是为了防止或减少 "过拟合现象" 的发生,是决策树具有更好的泛化能力。
剪枝分为“预剪枝”和“后剪枝”:
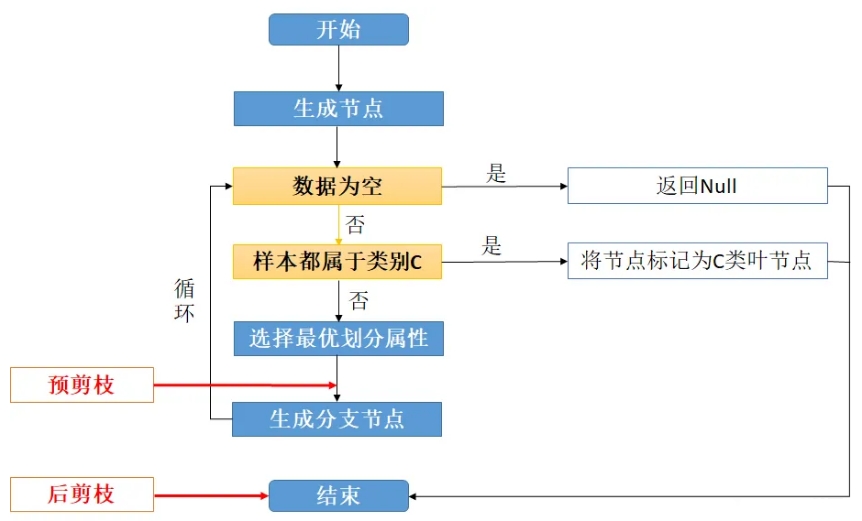
预剪枝:在决策树生成过程中,对每个结点在划分前先进性估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。它的位置在每一次生成分支节点前,先判断有没有必要生成,如没有必要,则停止划分。
后剪枝:先从训练集生成一棵完整的决策树(相当于结束位置),然后自底向上的对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点,相当于将子树剪去。值得注意的是,后剪枝时要用到一个测试数据集合,如果存在某个叶子剪去后能使得在测试集上的准确度或其他测度不降低(不变得更坏),则剪去该叶子。
05 优缺点
优点
①速度快:计算量相对较小,且容易转化成分类规则。只要沿着树根向下一直走到叶,沿途的分裂条件就能够唯一确定一条分类的谓词。
②准确性高:挖掘出的分类规则准确性高,便于理解,决策树可以清晰的显示哪些字段比较重要。
③非参数学习,不需要设置参数。
缺点
①决策树很容易过拟合,很多时候即使进行后剪枝也无法避免过拟合的问题,因此可以通过设置树深或者叶节点中的样本个数来进行预剪枝控制;
②决策树属于样本敏感型,即使样本发生一点点改动,也会导致整个树结构的变化,可以通过集成算法来解决。
声明:本网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!
相关推荐

人工智能(AI)和区块链技术近年来已成为革命性力量,推动各行各业的创新发展。《Act I: The AI Prophecy》立足于这两种技术的交汇点,提供了一个独特平台,致力于改善人工智能系统与人类及系统之间的互动方式。该项目运用区块链的去中心化特性,打造了一个开放协作的人工智能环境。在这里,用户突破传统互动模式的限制,而...

作为一个基于Tendermint共识的公链,Cosmos不同于大多数的区块链项目,其为开发者提供共识机制和应用开发工具(SDK),而非传统的执行引擎(虚拟机)。这一创新的模式为开发者提供了更高的自由度,允许他们按照自己的规格定制应用链的运行环境与交易类型,但是Tendermint共识机制的弊端在于很难实现去中心化的验证者节点网络...

多年来,Memecoin 一直是加密爱好者和业内资深人士关注的焦点。然而,这些代币容易成为诈骗、跑路和不正常代币分配模式的目标。为解决这些问题,ERC-7660 代币标准应运而生,旨在通过公平、公正、透明的方式推出 Memecoin,从而彻底改变 ERC20 代币的管理方式。本文将探讨 ERC-7660 的诞生背景、工作原理及其核心功能。关于...

以太坊 Pectra 升级(硬分叉)旨在全面提升以太坊的速度、可扩展性和便捷性,为普通用户和区块链开发者提供更优质的使用体验。这项重大升级预计于 2025 年正式启动,将分两个阶段实施,是近年来以太坊网络最重要的改进之一。Pectra 实际上融合了原计划单独进行的 Prague 和 Electra 升级。为了简化流程并确保顺利推进,这两...
网站所有相关资料如有侵权请联系站长删除,资料仅供用户学习及研究之用,不构成任何投资建议!| 联系邮箱:2751882518@qq.com 请注明来意! Copyright © 2024 Tuopo All Rights Reserved. XML地图
-学院-托破Tuopo")
-学院-托破Tuopo")